Préambule
Pour répondre aux besoins d’archivage et d’exploitation des documents d’entreprise et devant les possibilités offertes par les technologies issues d’Adobe (Imprimantes virtuelles PDF, outils de conversion pour PC ou AS400) d’enregistrer les spools d’impression des documents officiels au format PDF, EFALIA a développé le module ImportPDF .
Ce module permet la capture et l’indexation automatique des fichiers spool PDF dans les armoires de MultiGest.
Il est particulièrement adapté aux documents suivants :
- Fiches de paie
- Factures
- Bons de livraison
- Documents comptables
- …
Il permet ainsi la consultation rapide et l’édition à la demande de ces documents par les collaborateurs des entreprises habilitées par MultiGest.
Le but de ce module est de découper ce fichier pour obtenir un fichier par facture ou bulletin de paie puis d’importer tous ces fichiers PDF dans MultiGest en alimentant les champs d’index dont les informations ont été prélevées sur les factures ou les bulletins de paie.
Afin de traiter l’intégration de flux Spools PDF, il faut utiliser le module Import PDF de MultiGest pour traiter les flux puis le module Import Standard MultiGest pour intégrer les documents dans MultiGest.
Les étapes d’importation sont les suivantes :
- Le fichier PDF venant de l’outil métier doit être déposé sur le serveur GED,
- Le fichier PDF est découpé en plusieurs fichiers PDF accompagné d’un fichier CSV,
- Les fichiers PDF sont intégrés dans MultiGest via le module d’import de MultiGest.
Ensuite, il faut mettre en place une tâche planifié Windows afin de pouvoir automatiser le traitement de ces fichiers Spools PDF.
Cette documentation présente le fonctionnement pour l’importation des spools PDF et l’importation dans MultiGest en mode silencieux (sans utiliser le mode IHM).
Import des spools PDF
Afin de traiter l’import des spools PDF, il faut paramétrer les éléments à récupérer.
Afin de lancer l’outil de découpage, il faut exécuter le fichier .exe (IMPORTPDF_pix.EXE) avec le compte Administrateur dans le répertoire d’installation du module ImportPDF.

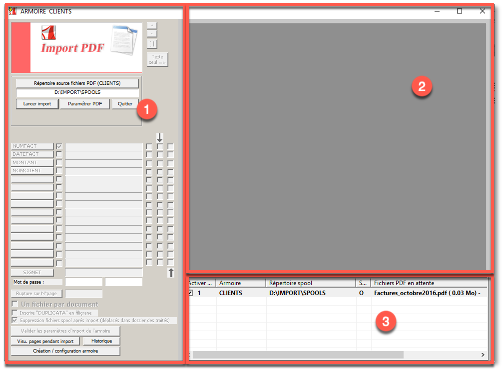
Cette interface propose 3 zones :
- Zone de paramétrage
- Zone de l’image PDF
- Zone de sélection de l’armoire
Paramétrage de l’import PDF
Pour lancer le paramétrage et créer une configuration pour l’import des factures, il faut cliquer sur le bouton « Création / Configuration armoire ».
Un nouvel écran s’affiche :
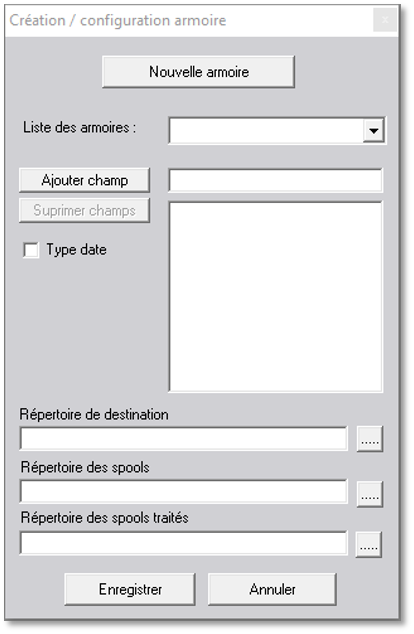
Cliquer sur le bouton « Nouvelle armoire ».
Saisir le nom de l’armoire dans laquelle les fichiers PDF vont être intégrés (exemple : CLIENTS) puis cliquer sur le bouton « Valider ».
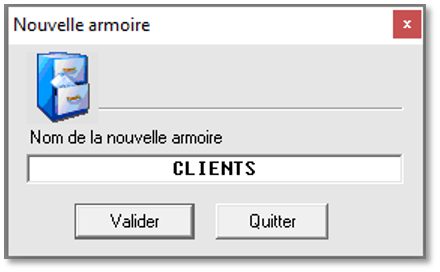
Suite à la création de l’armoire, une nouvelle fenêtre permet de paramétrer les informations de configuration de l’armoire.
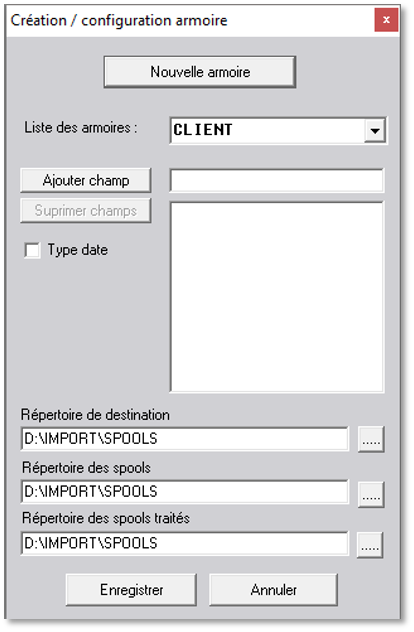
Pour ajouter un nouveau champ de récupération de données, saisir un nom de champ (exemple : NUMFACT pour N° Facture) puis cliquer sur le bouton « Ajouter un champ ».
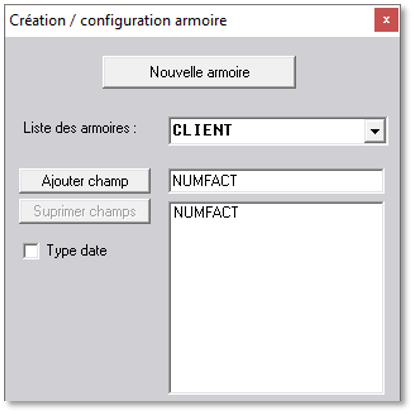
Ensuite, il faut répéter cette opération pour tous les champs qu’il faut créer.
Pour finaliser le paramétrage, il faut renseigner les différents chemins de traitement des fichiers :
- Répertoire de destination : Il s’agit du répertoire où les fichiers vont être déposés après traitement (un fichier CSV et n fichiers PDF)
- Répertoire des spools : Il s’agit du répertoire des fichiers sources (les fichiers spools PDF)
- Répertoire des spools traités : Il s’agit du répertoire où les fichiers spools sources vont être déposés à la fin du traitement
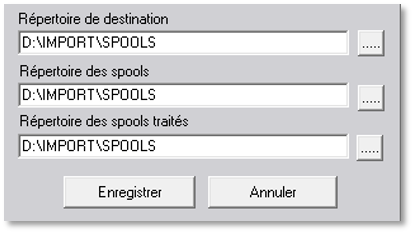
Cliquer sur le bouton [….] pour sélectionner les différents répertoires.
Enfin, cliquer sur le bouton « Enregistrer » pour sauvegarder la configuration.
Paramétrage des documents
Suite à la configuration de la nouvelle source, il faut maintenant paramétrer l’extraction PDF. Pour ce faire, il faut sélectionner l’armoire créée précédent en cochant « Activer appli N° » dans l’interface en bas à droite dans la zone de sélection de l’armoire. La ligne sélectionnée apparait alors en gras.

Il faut ensuite sélectionner le fichier source PDF. Il faut cliquer sur le bouton « Répertoire source fichiers PDF (CLIENTS) » dans notre exemple.
Une nouvelle fenêtre vous permet de sélectionner le répertoire source des fichiers PDF.
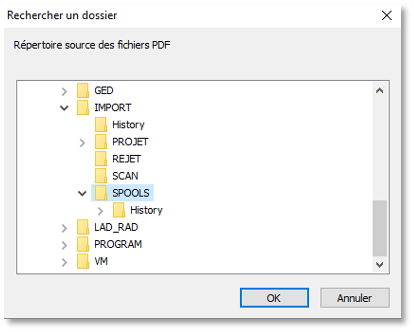
Sélectionner le répertoire où seront déposés les fichiers spools PDF venant de l’outil métier puis cliquer sur le bouton « OK »
Il faut ensuite cliquer sur le bouton « Paramétrer PDF ».
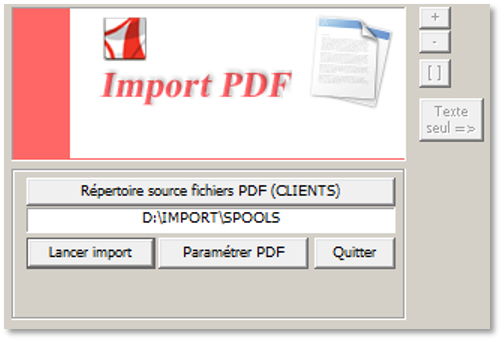
Une fenêtre vous permet de sélectionner le fichier PDF Source dans le répertoire paramétré précédemment (Cf. Répertoire des spools).
Cliquer sur le bouton « Ouvrir ».
Pour débuter le paramétrage des zones d’extraction, différents boutons sont disponibles.
| Icône | Description |
|---|---|
 | Ce bouton permet d’effectuer un zoom + (Agrandir) sur le document |
 | Ce bouton permet d’effectuer un zoom – (Réduire) sur le document |
 | Ce bouton permet de sélectionner les zones à récupérées dans la facture |
 | Ce bouton permet de ne pas afficher les images du fond de page (Logo / Tableau) pour permettre de n’afficher que les données métiers |
Pour sélectionner une zone, cliquez sur le bouton
et avec la souris, il faut encadrer la zone à récupérer.
Dans notre exemple, nous encadrons le n° de la facture.

Pour récupérer le n° de facture (Pour effectuer l’association d’un champ de l’armoire avec une chaîne de caractères dans la page PDF), cliquer sur NUMFACT pour voir apparaitre le numéro de facture et cocher la rupture.
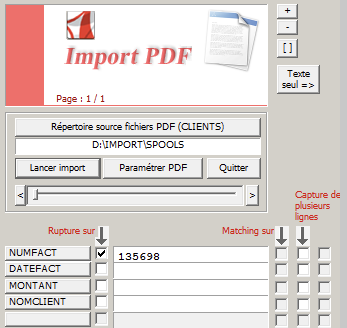
Ensuite, il faut effectuer la même opération pour la date de la facture, le montant de la facture et le nom du client prestation pour avoir le même écran ci-dessous :
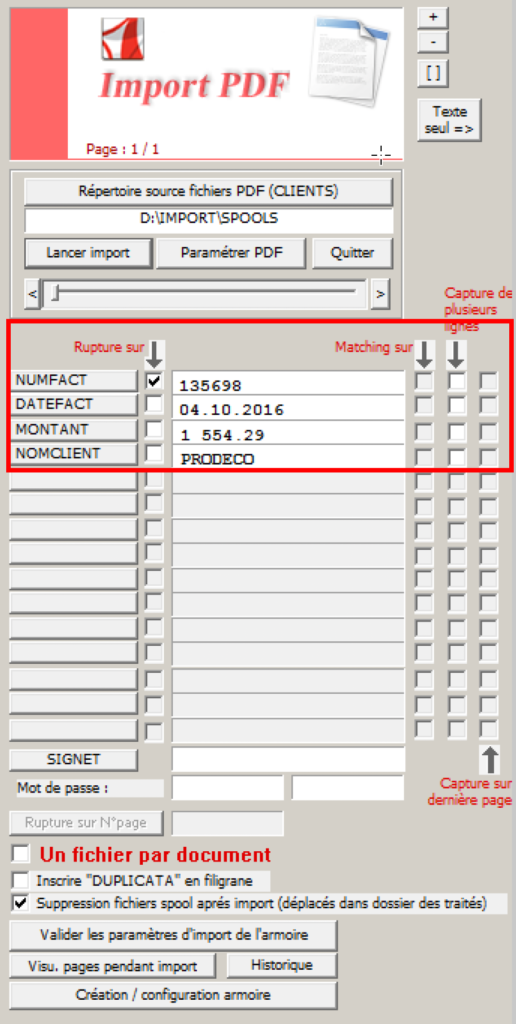
Différentes options sous forme de cases à cocher sont disponibles :
- Rupture sur : La rupture permet de spécifier les pages consécutives qui seront regroupées si la valeur du champ de rupture est identique.
- Remarque : Cas des factures à plusieurs pages avec rupture sur le N° de facture ou pour les fiches de paie avec rupture sur le matricule du collaborateur.
- Matching sur : Dans le cadre des applications de type PAIE, on peut regrouper automatiquement les pages, par matricule et année paie et ce, à chaque import mensuel.
- On obtiendra donc pour chaque individu un seul fichier PDF par année.
- Capture de plusieurs lignes : Cas si on souhaite récupérer une information sur plusieurs lignes (Cas des adresses par exemple)
D’autres options sont disponibles :
- Signet : Cliquer sur la chaîne de caractères dont la valeur devra apparaître en signets dans le PDF puis cliquer le bouton « Signet » (exemple : le mois pour la fiche de paie avril2016)
- Un fichier par document : Si le flux produit par l’application métier génére un fichier PDF par facture alors il faut cocher cette option
- Inscrire « DUPLICATA » en filigrane : Lors de la consultation des images, un filigrane DUPLICATA sera posé sur le document
- Suppression fichiers spool après import : Suite au traitement, le fichier spool d’origine sera déposé dans la répertoire défini précédemment (Répertoire des spools traités)
Ensuite, cliquer sur le bouton « Valider les paramètres de l’armoire ».
Il faut confirmer en cliquant sur le bouton « Oui », alors on obtient l’écran suivant :
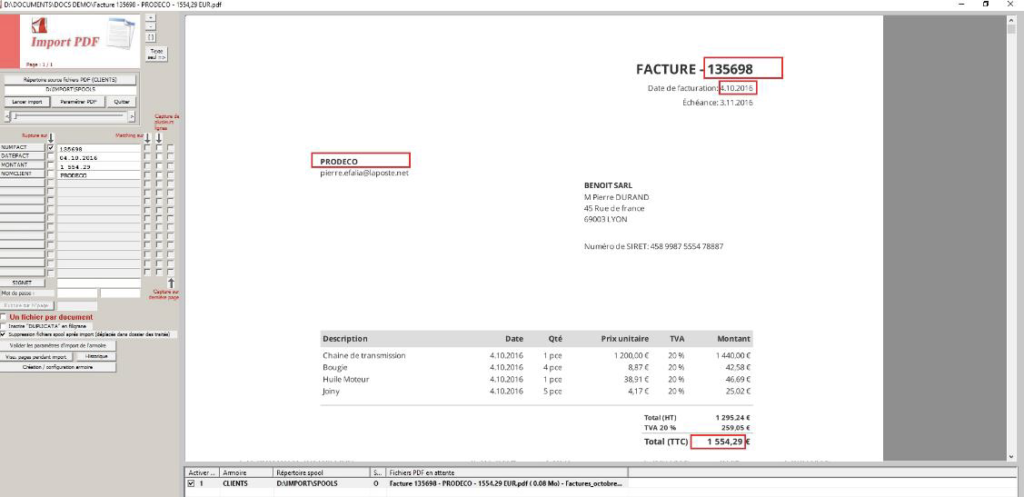
Les zones à récupérer sont encadrées en rouge.
Fichier de configuration
Suite au paramétrage, un fichier de configuration contenant les paramètres stockés est créé dans le répertoire d’installation de l’importPDF.
Exemple : D:\GED\APPLIS\ImportPDF\IMPORTPDF.INI
[ARMOIRES DECONNECTEES] 1=CLIENTS [CLIENTS] CHAMP0=ID (champ système pas de ligne ni colonne) CHAMP1=DATECREA (champ système pas de ligne ni colonne) CHAMP2=DATEREV (champ système pas de ligne ni colonne) CHAMP3=NUMFACT C 64 478 490 624 82 0 64 CHAMP4=DATEFACT C 64 483 1221 348 89 0 64 CHAMP5=MONTANT C 64 4203 2968 371 80 0 64 CHAMP6=NOMCLIENT C 64 794 1704 1528 133 0 64 REPSORTIE=D:\IMPORT\SPOOLS\TRAITE (Spools PDF traité) CHEMINLOT=D:\IMPORT\SPOOLS\IN (Spools PDF à importer) REPDEPLACE=D:\IMPORT\SPOOLS\OUT (Spools PDF Source après traitement) ACTIVE=O SUR_DERNIEREPAGE1= SUR_DERNIEREPAGE2= RUPTURE1=3 (numéro de champ pour rupture) RUPTURE2= MATCH1= MATCH2= CAPTURE SEQUENTIELLE= SIGNET=0 0 0 NPAGE=0 0 0 0 1 FICHIER 1 DOC=N (O/N indique si un fichier par document) SUPPRESSION=O (O/N indique si spools PDF sont supprimés après import) MOT DE PASSE= [FILIGRANE] CREER=0 (O/N indique si un filigrane est apposé sur le document)
Extraction via l’IHM de l’import PDF
Pour ouvrir le module de découpage des fichiers Spools PDF, cliquer sur l’icône de raccourci.

Pour lancer le traitement des fichiers spools, il suffit de placer le fichier spool dans le répertoire des sources puis de cliquer sur le bouton « Lancer l’import ».
Un message vous indique que l’import est terminé.
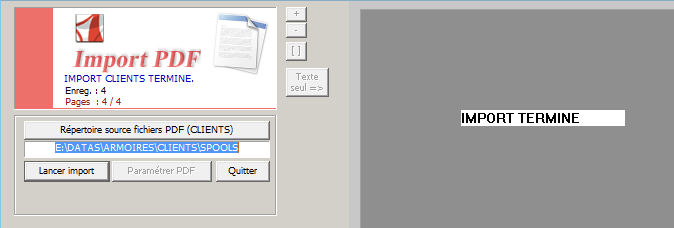
Résultat du découpage
Dans notre exemple de traitement des factures, le fichier PDF a été découpé en plusieurs fichiers PDF. Il y a autant de fichiers PDF qu’il y a de factures avec un fichier CSV qui l’accompagne.
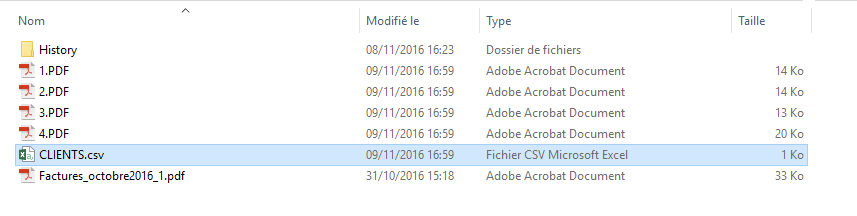
En ouvrant le fichier CSV, il est composé ainsi :

Sur l’exemple de la dernière ligne :
- Factures_octobre2016.pdf est le nom du fichier source
- 4 est le nom du fichier qui est 4.PDF
- 09/11/2016 est la date de réalisation du découpage
- FA154345 est le numéro de la facture
- 31/10/2016 est la date de la facture
- 13 540,00 est le montant TTC de la facture
- CLIENT4 est le nom du client
Import dans MultiGest
Pour lancer le module d’import, il suffit de lancer le fichier ImportMgest.exe qui se trouve dans le répertoire d’installation de l’import standard MultiGest en mode administrateur.

Pour sélectionner un modèle existant, il faut le choisir dans la liste.
| Icône | Description |
|---|---|
| Cette icône permet de créer un nouveau modèle | |
| Cette icône permet de modifier un modèle | |
| Cette icône permet de supprimer un modèle |
Nous allons paramétrer l’import pour le flux factures qui provient de l’import PDF.
Import de fichiers CSV
Informations générales
Ces informations dans la fenêtre de droite sont obligatoires à la création du modèle.
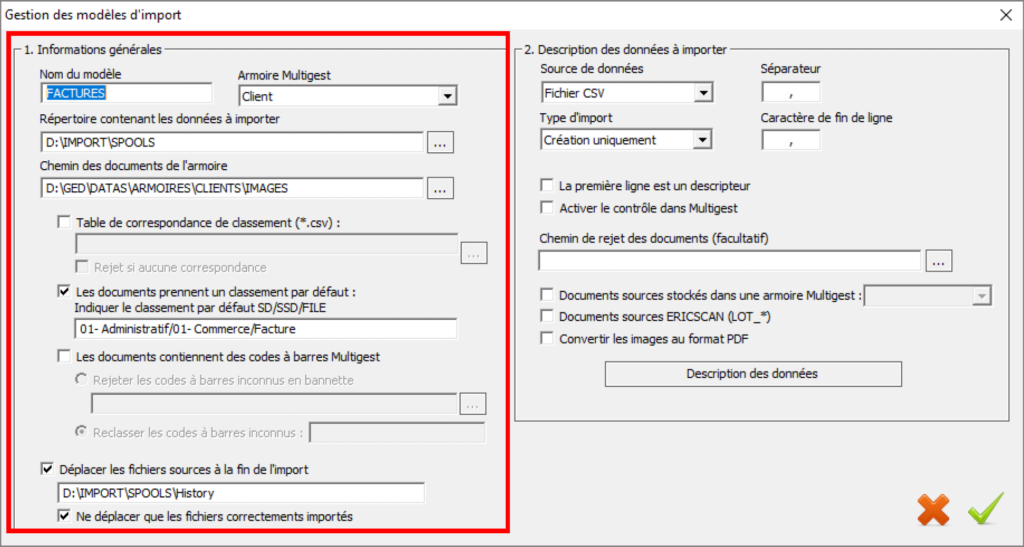
- Nom du modèle : Permet de saisir le nom du modèle
- Armoire MultiGest : Sélection de l’armoire de destination dans MultiGest
- Répertoire contenant les données à importer : Ce repertoire est le répertoire où vont être déposés les données à importer (les fichiers ainsi que le fichier d’index au format CSV provenant de l’import PDF)
- Chemin des documents de l’armoire : Ce chemin des armoires se renseigne automatiquement à la sélection de l’armoire. Selon le poste depuis lequel le programme est exécuté, ce chemin peut être modifié.
Dans le cas de l’importation de fichiers associés au CSV, il faut cocher l’option qui indique que les documents prennent un classement par défaut.
Dans la cas d’une armoire en mode dossier, il faut indiquer un classement par défaut des images à importer. Pour cela il faut indiquer :
- SD pour le sous dossier
- SSD pour le sous sous dossier
- FILE pour le fichier
Dans notre exemple, les factures vont aller se classer dans un dossier du plan de classement (dans le sous dossier 01- Administratif, dans le sous sous dossier 01- Commerce et dans la rubrique Facture).
Enfin, l’option « Déplacer les fichiers sources à la fin de l’import » permet de déplacer les données importées dans le répertoire « History » créé automatiquement dans le répertoire d’import.
Pour chaque import, un répertoire « Import du JJ-MM-AAAA HH-MM-SS » dans ce répertoire « History ».
Description des données à importer
Les autres champs de cette interface permettent de décrire le type d’import à définir.
La définition de la source de données permet de sélectionner l’option « Fichier CSV ».
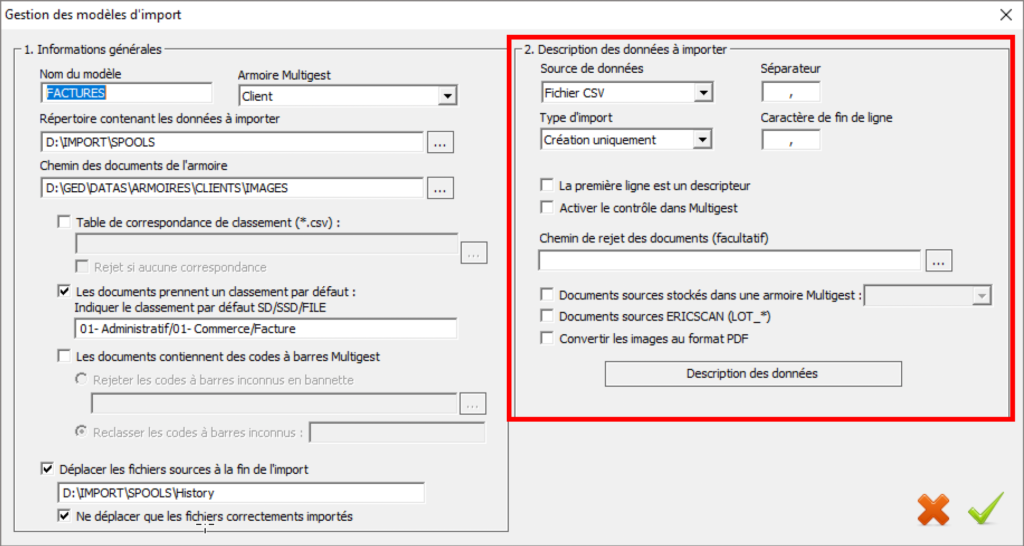
- Source de données : Sélectionner l’option Fichier CSV
- Fichier CSV : Un fichier « .CSV » accompagne les documents à importer issu de la phase de découpe PDF (Cf. Résultat du découpage) ou d’un fichier produit par une application tierce. Ce fichier « .CSV » se trouve toujours dans le même répertoire que les documents à importer.
- Type d’import : Sélectionner le type d’import à effectuer
- Création uniquement : Pour chaque document, un index GED est créé à partir des données contenues dans le fichier CSV
- Matching uniquement : Les données du fichier CSV vont permettre de chercher le dossier dans lequel le document doit être importé. Si la recherche ramène plusieurs dossiers, le document est rejeté.
- Création et matching : Les données du fichier CSV vont permettre de vérifier si le dossier existe déjà. S’il n’existe pas, il est créé.
- Séparateur : Il s’agit du caractère dans le fichier CSV qui sépare les differentes valeurs.
Dans le cas de l’import spool au format PDF, le séparateur est la virgule (,)
- Caractère de fin de ligne : Il s’agit du caratère délimitant le fin d’un enregistrement avant un nouvel enregistrement. Dans le cas le cas de l’import spool PDF, le caractère de fin de ligne est la virgule (,)
- La première ligne est un descripteur : Cette option permet d’indiquer que la première ligne du fichier CSV n’est pas à importer et sert seulement à décrire les colonnes du fichier CSV. Dans le cas de notre exemple, il n’y a pas de première ligne qui décrive les différentes valeurs récupérées
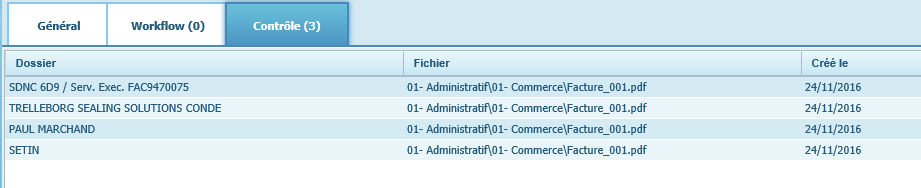
- Activer le contrôle dans MultiGest : Les données ne sont pas directement importées dans la GED mais vont être proposées à un utilisateur dédié, via l’onglet « Contrôle » pour valider les factures avant de les importer.

- Chemin de rejet des document (Facultatif) : Lorsque l’import ne s’effectue pas (Par exemple, problème d’une zone non lisible due à l’apposition d’un tampon sur la valeur), il est possible de déposer les documents en erreur dans une bannette de Mutligest pour les classer manuellement en GED ou dans un répertoire sur le serveur pour traiter les rejets
- Documents sources stockés dans une armoire Mutligest : Cette option permet de conserver le flux original PDF dans une armoire pour garder un historique des flux traités directement en GED
- Documents sources ERICSCAN
- Convertir les images au format PDF : Cette option propose lors de l’intégration d’images TIFF ou de documents via l’import MultiGest de convertir les documents au format PDF

Lors de l’importation des fichiers CSV, il faut définir la description des données à importer en cliquant sur le bouton « Description des données ».
Une nouvelle fenêtre s’ouvre pour la définition de ces éléments :
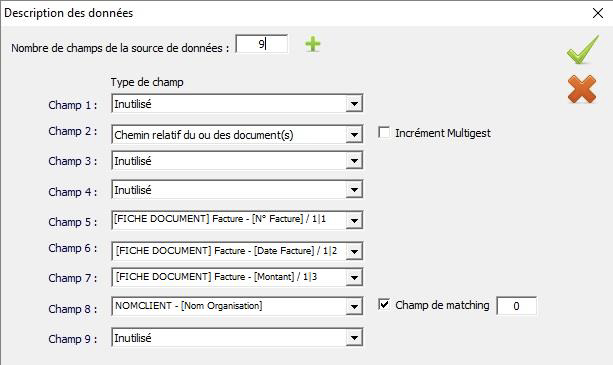
Cet écran permet de faire le lien entre les données récupérées et les données de destination dans l’armoire.
En effet, comme vu précédemment, un fichier CSV est produit suite au traitement des flux spools PDF (Cf. Résultat du découpage).

Cet interface permet donc de définir les champs sources et les champs de destination.
Dans notre exemple, le nombre de champ permet de définir le nombre de valeurs à récupérer dans la fichier CSV. Ici, dans le fichier CSV, il suffit de compter le nombre de valeurs séparés par la virgule en comptant les champs vides (caractère séparateur de valeur).
Il faut donc indiquer 9 dans le nombre de champ.
Ensuite, il faut effectuer le mapping :
- Champ 1 : Il s’agit du nom du fichier spool PDF original
- Inutilisé (Pas de destination dans la GED)
- Champ 2 : Il s’agit du N° du fichier de la facture découpée
- Chemin relatif du ou des documents
- Champ 3 : Date d’extraction du fichier
- Inutilisé (Pas de destination dans la GED)
- Champ 4 : Date de modification du fichier (Vide)
- Inutilisé (Pas de destination dans la GED)
- Champ 5 : N° de la facture
- Mapping sur le champ N° de facture dans la fiche de métadonnées FACTURE
- Champ 6 : Date de la facture
- Mapping sur le champ Date facture dans la fiche de métadonnées FACTURES
- Champ 7 : Montant de la facture
- Mapping sur le champ Montant dans la fiche de métadonnées FACTURES
- Champ 8 : Nom du client
- Mapping sur le champ Nom organisation dans la fiche de métadonnées du dossier CLIENT
- Champ de matching : Association de la facture en fonction de l’information sur le Nom du client. Lors de l’import, la solution recherche si le nom de l’organisation existe dans la GED et va associer la facture à cette organisation.
- Champ 9 : Champ Vide
- Inutilisé (Pas de destination dans la GED)
Importation via le nom du document
Informations générales
La définition de la source de données permet de sélectionner l’option « Nom du document ».
Les informations de description du document sont contenus dans la nom physique du fichier (exemple : FACTURE_NOMFOURNISSEUR_N° Facture.pdf ou BONDECOMMANDE_NOMFOURNISSEUR_N° Bon de commande).
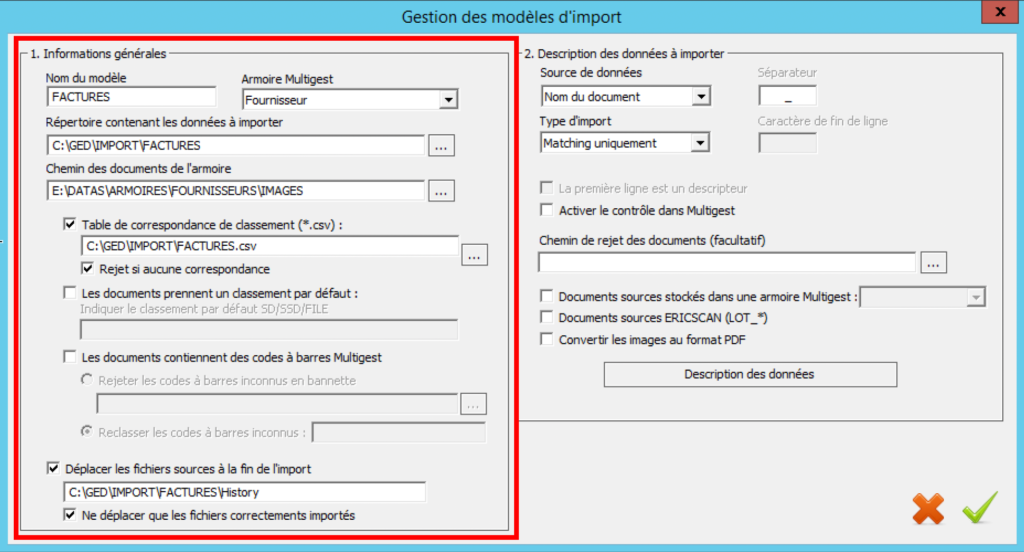
- Nom du modèle : Permet de saisir le nom du modèle
- Armoire MultiGest : Sélection de l’armoire de destination dans MultiGest
- Répertoire contenant les données à importer : Ce repertoire est le répertoire où vont être déposés les documents à importer
- Chemin des documents de l’armoire : Ce chemin des armoires se renseigne automatiquement à la sélection de l’armoire.
- Selon le poste depuis lequel le programme est exécuté, ce chemin peut être modifié.
Dans le cas de l’importation de fichiers nommés, il faut cocher l’option qui indique que les documents vont être classés selon une table de correspondance de classement.
En effet, il faut créer un fichier CSV qui est une table de correspondance pour classer les documents dans la GED.
Exemple : Factures.csv
;;Facture;03-Facturation;;Facture; ;;Bon de commande;03-Facturation;;Bon de commande;
Inutilisé ; Inutilisé ; Type de document ; Sous Dossier ; Sous Sous Dossier ; Fichier
Cela signifie, que les documents commençant par Facture se classeront dans le dossier du fournisseur dans le sous dossier 03-Facturation et le fichier sera nommé Facture (Dans notre exemple, nous n’avons pas défini de sous sous dossier).
Avant import :
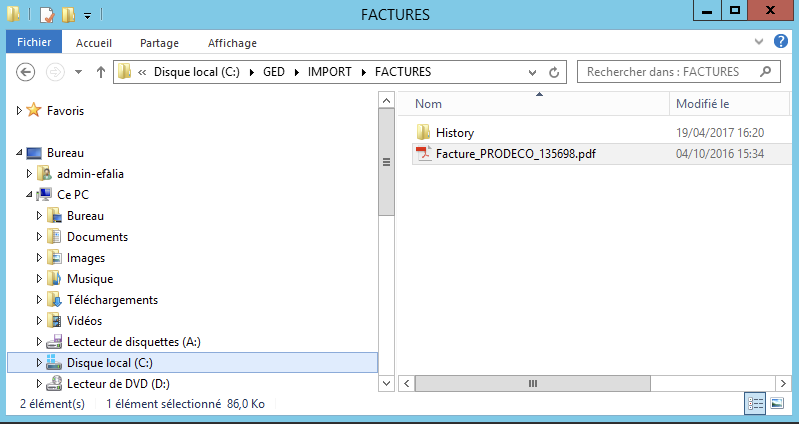
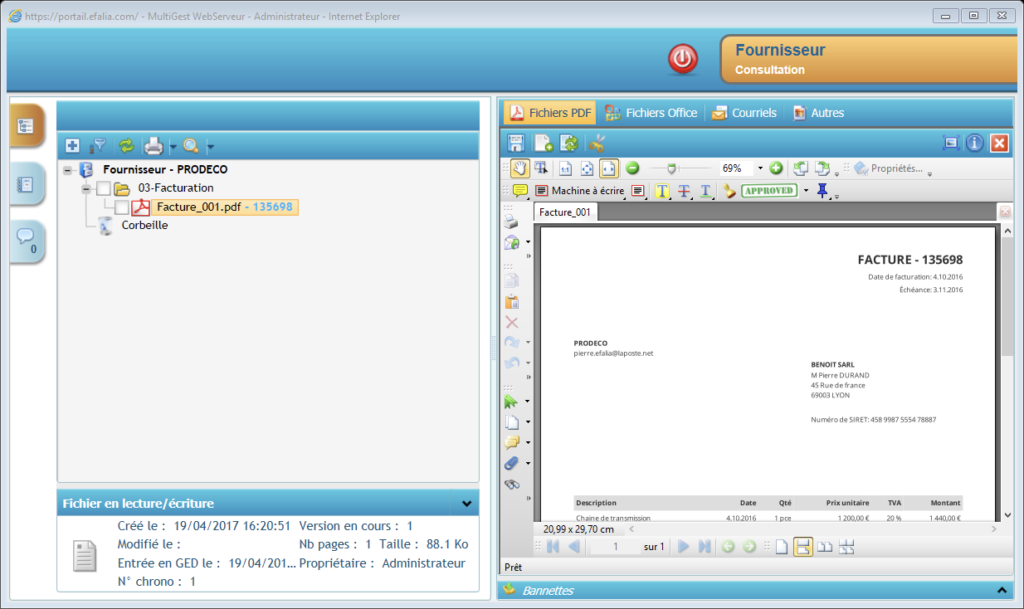
Après import :
Dans le plan de classement de la GED
A la fin de l’import, un fichier de log vous permet de savoir si l’importation s’est déroulée correctement.
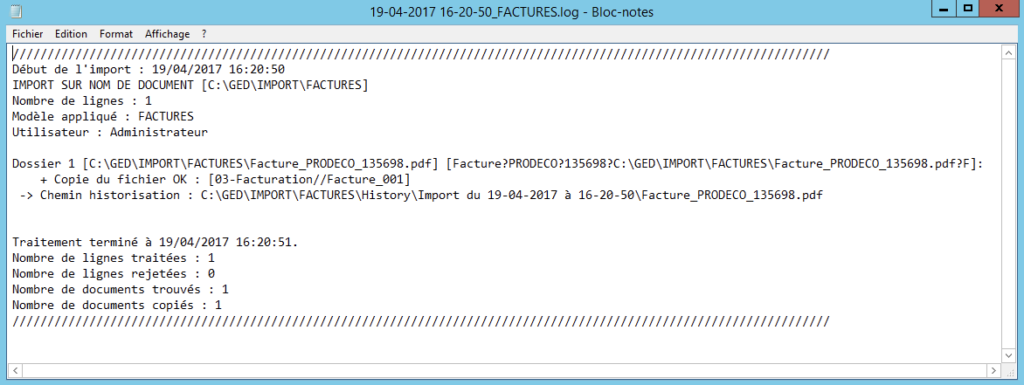
Enfin, l’option « Déplacer les fichiers sources à la fin de l’import » permet de déplacer les données importées dans le répertoire « History » créé automatiquement dans le répertoire d’import.
Pour chaque import, un répertoire « Import du JJ-MM-AAAA HH-MM-SS » dans ce répertoire « History ».
Description des données à importer
Les autres champs de cette interface permettent de décrire le type d’import à définir.
La définition de la source de données permet de sélectionner l’option « Nom du document ».
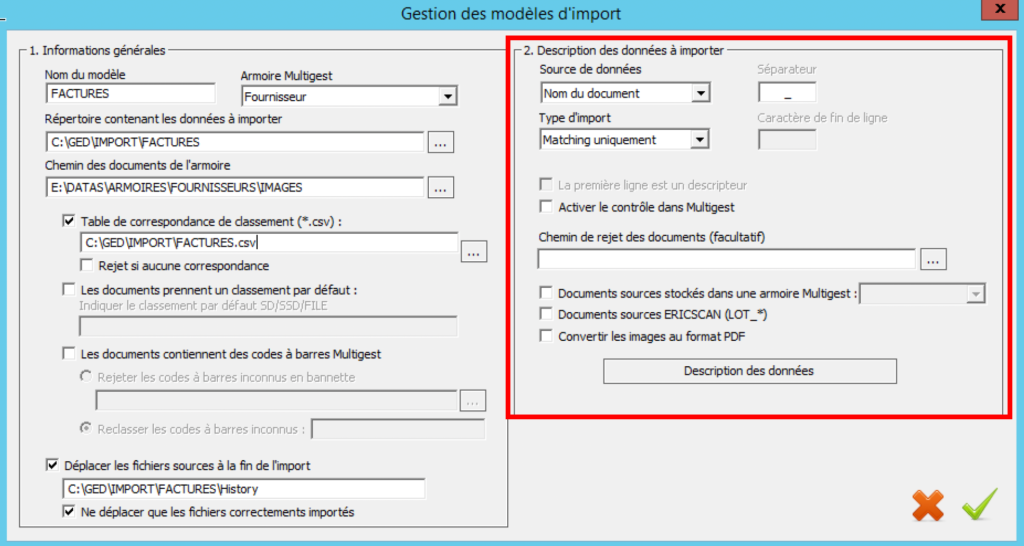
- Source de données :
- Nom du document : le nom du document est construit avec des données qui seront utilisés pour l’import pour créer des dossiers MultiGest. Le nom du fournisseur ainsi que le n° de la facture seront utilisés pour classer le document dans un dossier d’une armoire
- Type d’import : Sélectionner le type d’import à effectuer
- Création uniquement : Pour chaque document, un index GED est créé à partir des données contenues dans le nom du fichier
- Matching uniquement : Les données dans le nom du fichier vont permettre de chercher le dossier dans lequel le document doit être importé. Si la recherche ramène plusieurs dossiers, le document est rejeté.
- Création et matching : Les données dans le nom du fichier vont permettre de vérifier si le dossier existe déjà. S’il n’existe pas, il est créé.
- Séparateur: Il s’agit du caractère séparateur des données dans le nom du document ( _ ) qui sépare les differentes valeurs.
- Caractère de fin de ligne : Non utilisé (Grisé)
- La première ligne est un descripteur : Non utilisé (Grisé)
- Activer le contrôle dans MultiGest : Les données ne sont pas directement importées dans la GED mais vont être proposées à un utilisateur dédié, via l’onglet « Contrôle » pour valider les factures avant de les importer.
Lors de l’importation des fichiers, il faut définir la description des données à importer en cliquant sur le bouton « Description des données ».
Une nouvelle fenêtre s’ouvre pour la définition de ces éléments :
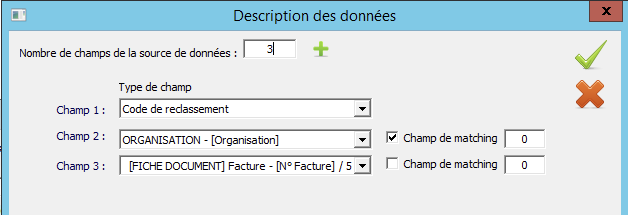
Cet écran permet de faire le lien entre les données récupérées et les données de destination dans l’armoire.
Cet interface permet donc de définir les champs sources et les champs de destination des données lues dans le nom du fichier.
Il faut donc indiquer 3 dans le nombre de champ.
Ensuite, il faut effectuer le mapping :
- Champ 1 : Il s’agit du code de classement
- Sélectionner le code de classement
- Champ 2 : Il s’agit du Nom de l’organisation (Fournisseur)
- Le matching va se faire sur cette valeur, c’est-à-dire que si il trouve dans la GED un dossier existant avec cette valeur alors l’import va classer le document dans le dossier correspondant au nom du fournisseur
- Champ 3 : Il s’agit du N° de facture
- L’information récupérée dans le nom du fichier (c’est-à-dire la 3ème valeur) renseignera le champ N° Facture pour les données de description de l’entité Facture dans la GED.
Mise en place de la tâche planifiée Windows
Création d’un fichier *.bat
Afin de pouvoir traiter les flux en mode silencieux, il faut dans un premier temps créer un fichier .bat.
Voici un exemple de fichier .bat : Import_PDF_Factures.bat
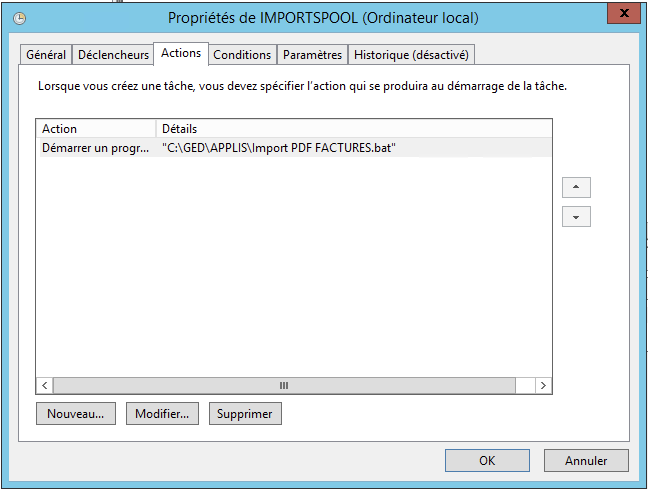
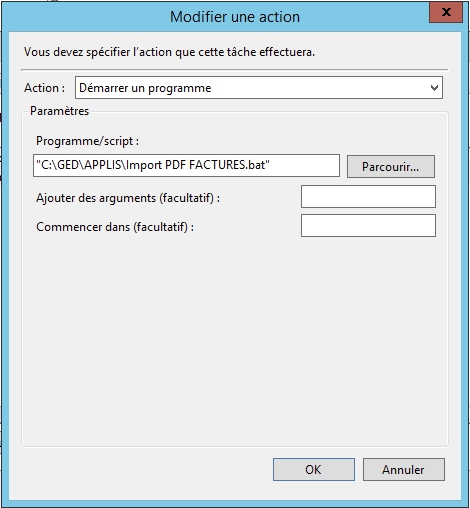
C: cd "C:\GED\APPLIS\ImportPDF" IMPORTPDF_pix.exe A CSV CLIENTS C: cd "C:\GED\APPLIS\Import Standard" ImportMgest.exe -MFACTURES -Uadmin
Pour les paramètres de l’import PDF en mode déconnecté :
- A : en mode silencieux
- CSV : pour mode déconnecte (CSV remplace le nom du serveur)
- ARMOIRE : nom de l’armoire
Pour les paramètres de l’import PDF en mode connecté :
- A : en mode silencieux
- SERVEUR : nom du serveur
- ARMOIRE : nom de l’armoire
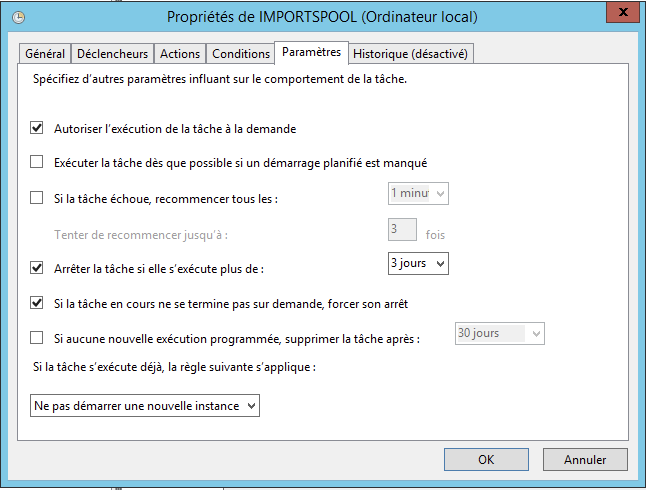
Créer un tâche automatique Windows
- Ensuite, il faut lancer le planificateur de tâches Windows.
- Aller dans le Panneau de configuration, Outils d’administration puis Planificateur de tâches.
- Dans Bibliothèque de Planificateur de tâches, créer un nouveau dossier (exemple : MultiGest)
- Créer une nouvelle tâche (exemple : ImportSpools)
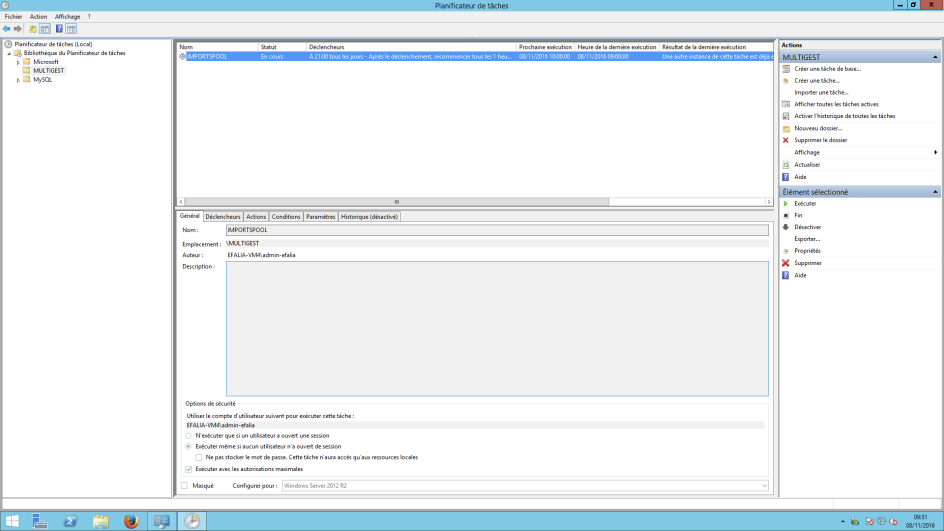
Nous allons voir les différentes étapes pour paramétrer cette tâche.
Onglet Général
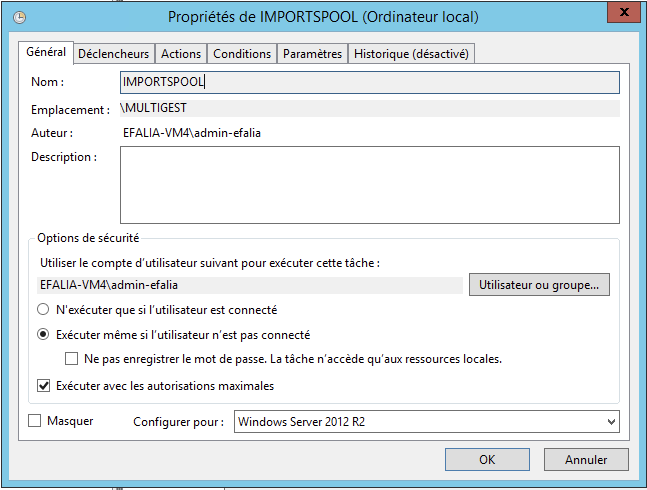
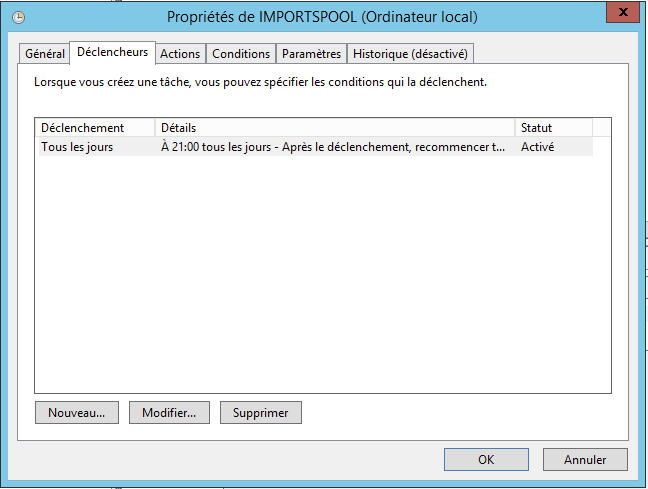
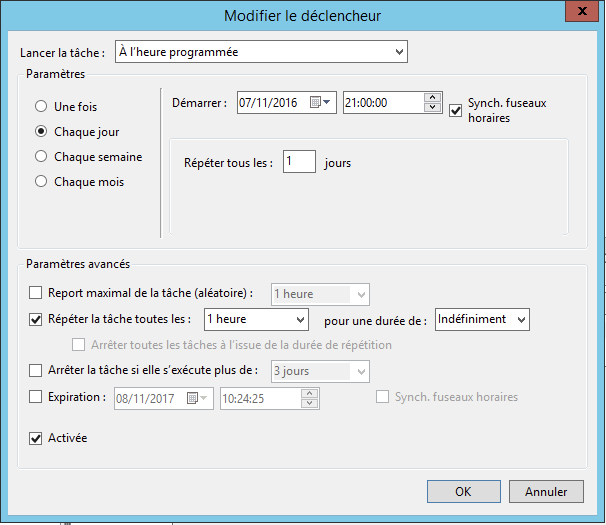
Onglet Déclencheurs
Onglet Actions
Onglet Conditions
Onglet Paramètres