Le programme d’import de documents a été conçu pour importer dans Multigest des documents de différentes provenances :
- Documents produits par des outils de prestation de numérisation
- Documents produits par un système type « eCopy »
Ce programme peut traiter différentes sources de données destinées à différentes destinations (armoires de Multigest) grâce à la création de modèles d’import.
Tous ces imports sont tracés :
- Dans Multigest par les logs de l’observateur d’évènement
- Dans les logs de traitement du module d’import
Fonctionnement général
Deux modes de fonctionnements sont disponibles :
Fonctionnement via l’interface
L’interface de l’application permet d’administrer les modèles d’import et de réaliser les traitements d’import :
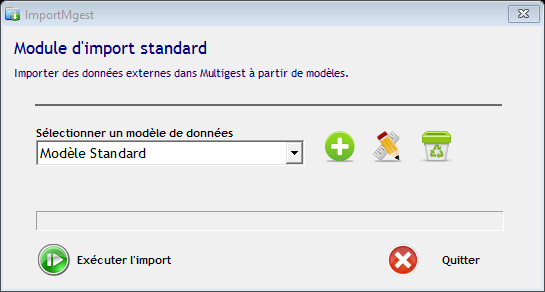
- Bouton de création, de modification ou de suppression d’un modèle
- Bouton de lancement de l’import basé sur le modèle sélectionné
- Liste déroulante de sélection d’un modèle existant
- Bouton de lancement de l’import basé sur le modèle sélectionné
- Bouton de création, de modification ou de suppression d’un modèle
Les modèles créés sont enregistrés dans le répertoire d’installation du Module d’Import Standard dans le sous-répertoire « Modèles ». Ces modèles sont des fichiers avec une extension « .mds ». Ils ne doivent pas être supprimés.
Exemple : D:\GED\Import Standard
Les logs de traitement sont enregistrés dans le répertoire d’installation du Module d’Import Standard dans le sous-répertoire « Logs ».
Fonctionnement en Mode Silencieux
Pour ce fonctionnement, le programme doit être exécuté avec des arguments passés en ligne de commande, soit depuis un fichier « bat », soit depuis un raccourci.
Ce mode peut être couplé aux tâches planifiées Windows pour un fonctionnement 100% automatique.
Exemple : ImportMgest.exe –M[Nom du modèle] –U[Utilisateur]
Description des sources de données
Bouton de lancement de l’import basé sur le modèle sélectionné
Les sources de données pouvant être importées avec ce programme peuvent être importées de deux manières:
Fichier de description « csv » et documents
Les documents et le fichier csv sont placés dans le répertoire d’import.
Ce fichier *.csv doit posséder pour chaque ligne les données suffisantes pour décrire :
- Les données qui vont permettre de créer ou de rechercher l’index Multigest pour auquel les documents seront associés
- L’emplacement du document lié à chaque ligne du csv
- Ce fichier peut également contenir des métadonnées qui décrivent le classement du document dans le dossier où il sera importé. Ces métadonnées sont les suivantes :
- Sous-dossier de classement
- Sous-sous-dossier de classement
- Nom du fichier
Documents seuls
Dans ce cas, c’est le nom du document qui précise les données qui vont permettre de créer ou de rechercher un dossier dans Multigest.
Documents produits par eCopy
Les documents produits par eCopy sont créés selon un format standard préconisé par EFALIA.
Chaque document produit est associé à un fichier csv portant le même nom que le document.
Ce fichier csv possède également des données pour créer ou rechercher l’index et peut contenir des métadonnées.
Création et modification de modèles
Il faut cliquer sur le bouton
pour créer un nouveau modèle.
L’écran suivant permet de gérer ce modèle d’import. La définition d’un modèle se fait en deux étapes :
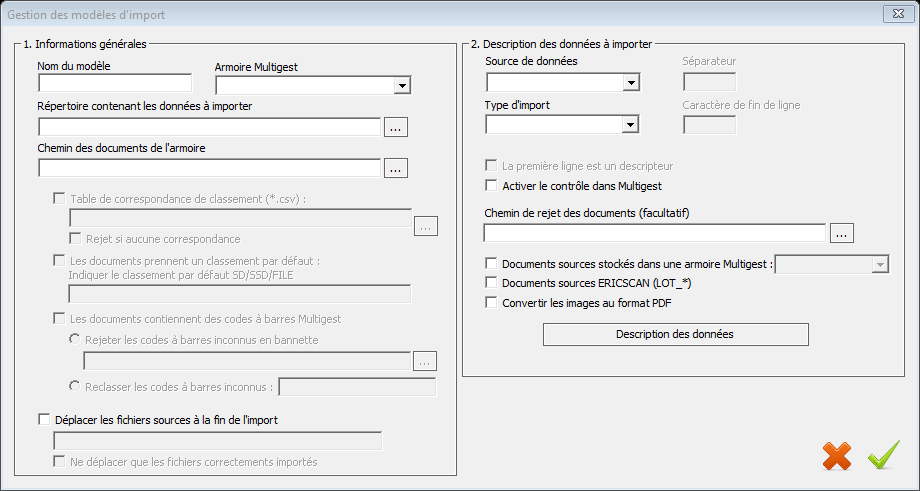
Zone d’informations générales du modèle
Cette zone vous permet de définir les options générales de l’import.
Tous les champs suivant sont obligatoires :
- Le nom du modèle
- L’armoire Multigest de destination
- Le répertoire contenant les données à importer (Ex : D:\GED\IMPORT)
- Le chemin des armoires se renseigne automatiquement à la sélection de l’armoire.
Suite aux renseignements des précédentes valeurs, il faut définir le mode de classement des documents importés (uniquement dans le cas des armoires en mode dossier).
Table de correspondance de classement (*.csv) : Cette table de reclassement est un fichier csv de 6 colonnes (avec séparateur « ; » et caractère de fin de ligne « ; »)
- Sous-dossier du document source
- Sous-sous-dossier du document source
- Nom du document source (sans extension)
- Sous-dossier du document destination
- Sous-sous-dossier du document destination
- Nom du document destination (sans extension)
Exemple d’un fichier de reclassement :

Définition d’un classement par défaut : il s’agit d’une chaine de caractère qui décrit le sous-dossier, sous-sous-dossier et nom du fichier (sans extension) qui correspond au plan de classement. Le séparateur est le « / ».
Exemple : 01- Administratif/01- Commerce/Facture
Reconnaissance de codes à barres Multigest : Cette option permet d’utiliser la fonctionnalité des codes à barres Multigest
Déplacer les fichiers sources à la fin de l’import : Cette option permet de déplacer les données importées dans le répertoire « History » créé automatiquement dans le répertoire d’import.
Pour chaque import, un répertoire « Import du JJ-MM-AAAA HH-MM-SS » dans ce répertoire « History ».
Zone de description des données à importer
Les autres champs de cette interface permettent de décrire le type d’import et le type de fichier csv.
Source de données :
- Fichier CSV: un fichier « csv » accompagne les documents à importer. Ce fichier « csv » se trouve toujours dans le même répertoire que les documents.
- Nom du document : le nom du document est construit avec des données qui seront utilisés pour l’import pour créer ou rechercher des dossiers Multigest
- eCopy : chaque document est accompagné d’un fichier « csv ». Le document et le fichier « csv » portent le même nom.
Type d’import :
- Création uniquement : pour chaque document, un index GED est créé à partir des données contenues dans le fichier « csv » ou dans le nom du document
- Matching uniquement : les données du fichier « csv » ou contenues dans le nom du document vont permettre de chercher le dossier dans lequel le document doit être importé. Si la recherche ramène plusieurs dossiers, le document est rejeté
- Création et matching : les données du fichier « csv » ou contenues dans le nom du document vont permettre de vérifier si le dossier existe déjà. S’il n’existe pas, il est créé.
Les champs « séparateur » et « caractère de fin de ligne » permettent d’extraire les données du fichier « csv » ou contenues dans le nom du document.
Le champ « La première ligne est un descripteur » permet d’indiquer que la première ligne du fichier csv n’est pas à importer et sert seulement à décrire les colonnes du fichier « csv ».
Il faut cliquer sur le bouton « Description des données » pour pouvoir paramétrer les correspondances.
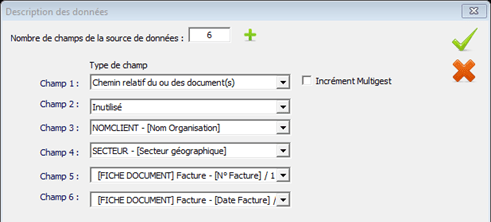
Dans un premier temps, il faut définir le nombre de colonnes du fichier « csv » ou contenues dans le nom du document.
Pour chaque champ, il s’agit d’indiquer quel rôle jouera ce champ lors de l’import :
- Chemin relatif du ou des documents
- Inutilisé
- Sous-dossier de classement (mode dossier seulement)
- Sous-sous-dossier de classement (mode dossier seulement)
- Nom du fichier (mode dossier seulement)
- Champ de l’armoire pour la création par défaut et pour le matching si la case à cocher « Champ de matching » est activée
Lecture des logs de traitement
Pour chaque import, un fichier de log est créé dans le répertoire d’installation de l’import standard : « JJ-MM-AAAA HH-MM-SS.log »
Exemple d’un fichier de log :
