L’accès aux tâches planifiées s’effectue dans le menu « Tâches planifiées » accessible depuis le Menu Administration.

Voici l’interface des tâches planifiées :
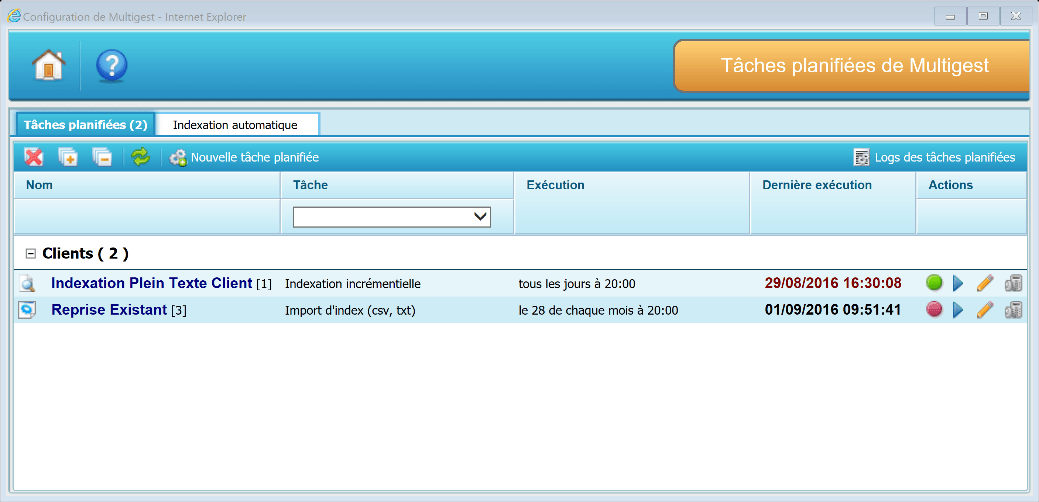
Pour créer une nouvelle tâche planifiée, il faut cliquer sur le bouton « Nouvelle tâche planifiée ».
La fenêtre suivante apparait :
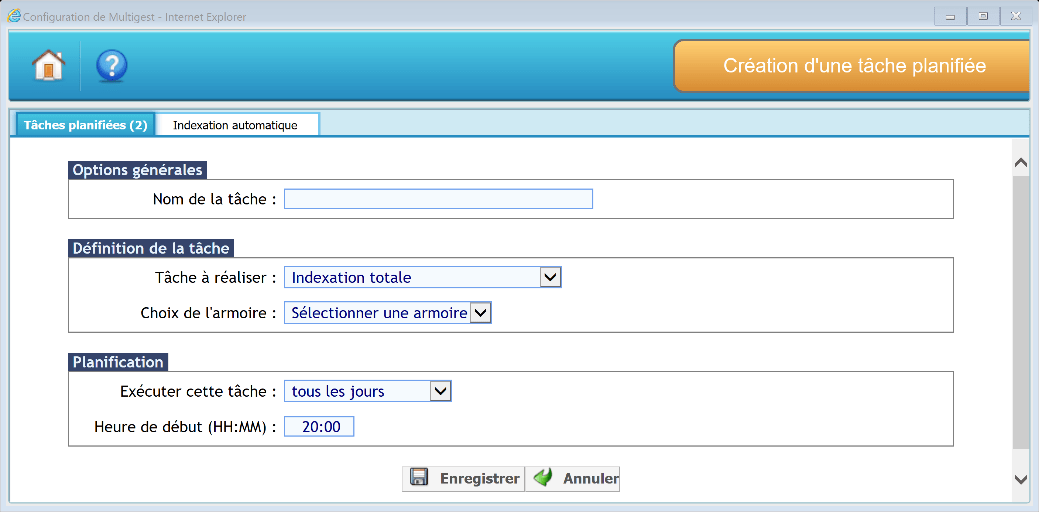
Nous renseignons ici les informations suivantes :
- Nom de la tâche
- Choix de l’armoire
- Tâche à réaliser (indexation totale dans l’exemple)
- La planification par jour et par heure
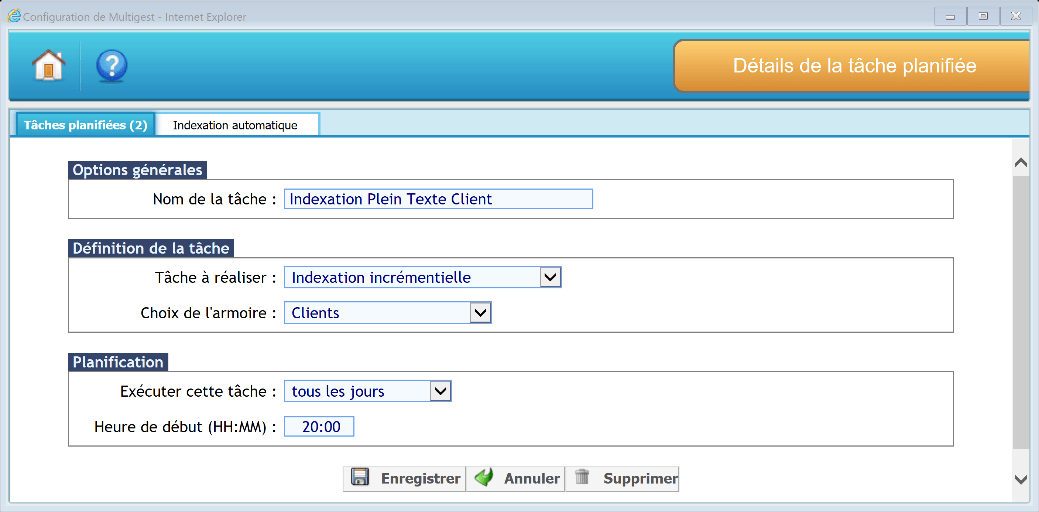
Les tâche d’indexation
Une action d’indexation est obligatoire pour rendre l’armoire compatible avec une recherche sur contenu dite plein texte.
Il s’agit en fait d’indexer dans des dictionnaires spécifiques tous les mots contenus dans les différents documents et ce afin de permettre une recherche de toutes les instances de ces mots dans telle ou telle page d’un document.
Indexation totale
Cette tâche permet une indexation plein texte de l’intégralité des documents présents dans le répertoire de stockage de l’armoire
Indexation incrémentielle
Cette tâche permet une indexation plein texte partielle concernant uniquement les documents qui n’ont pas été indexés jusqu’à présent.
Les tâches d’import
Ces différentes opérations permettent d’alimenter les armoires de la GED avec soit :
- des nouvelles données
- des documents
- des couples « image + fichier d’indexation »
Import d’index
Ce type d’import permet d’alimenter les données d’une armoire GED avec de nouveaux enregistrements, provenant d’un fichier texte.
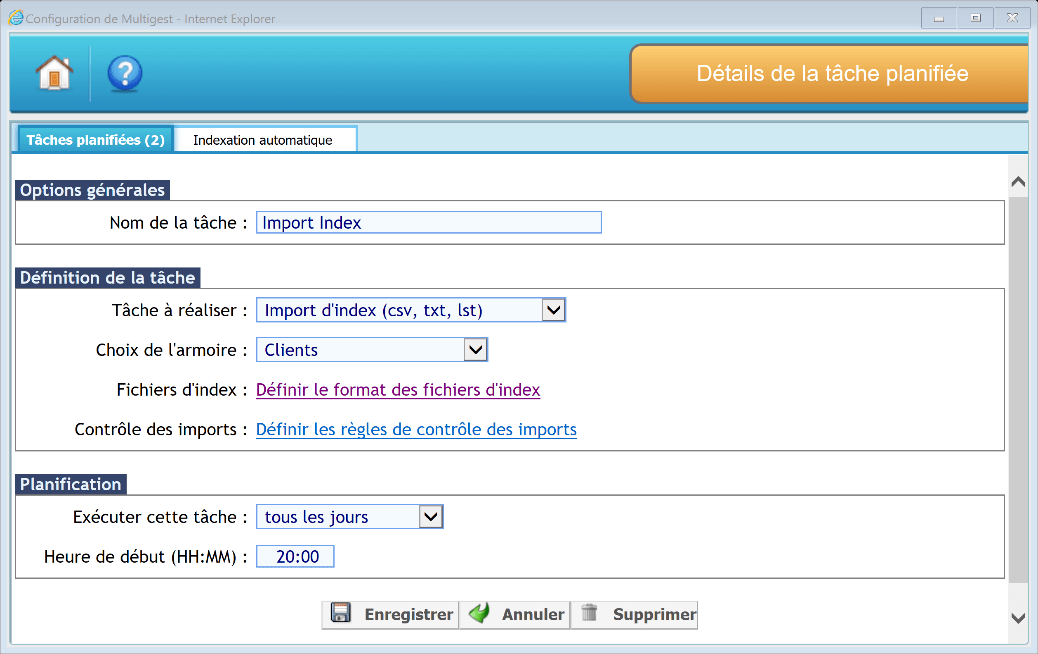
Options générales :
Il faut donner un nom explicite à la tâche afin de pouvoir la tracer dans l’observateur d’évènements.

Définition de la tâche :
Il faut définir des paramètres pour la tâche :
- Type de tâche à réaliser : Import d’index (csv,txt,lst)
- Choix de l’armoire : Choisir l’armoire de destination
- Fichiers d’index : Définir le format des fichiers d’index
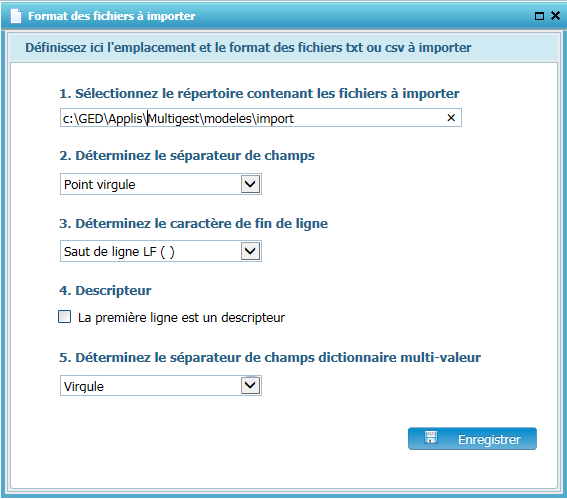
Définition de cinq paramètres :
- Chemin d’accès au fichier
Séparateur de champ avec ces choix possibles :

- Caractère de fin de ligne
Possibilité de cocher « la première ligne est un descripteur ». Dans ce cas, la première ligne du fichier ne sera pas importée car étant un descripteur de la structure du fichier.
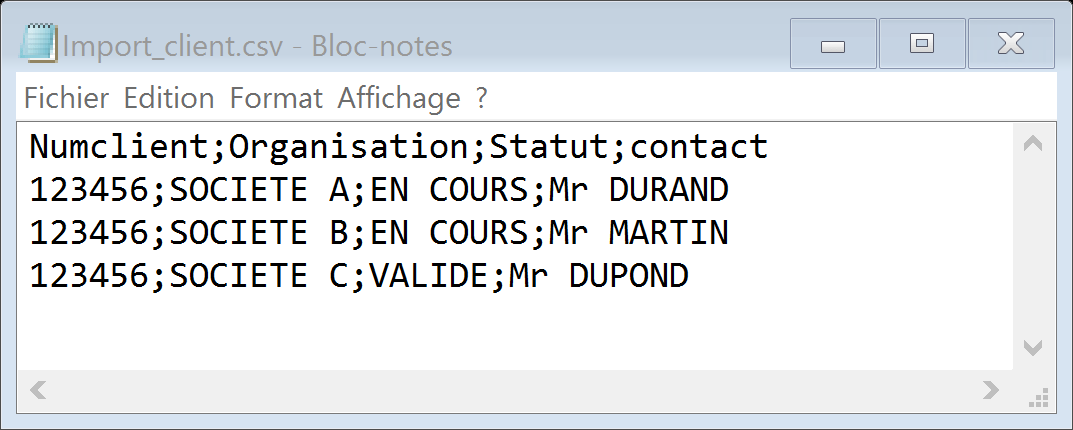
Déterminez le séparateur de champs dictionnaire multi-valeur. Dans le cas des champs dictionnaires en « Sélection Multiple » il est nécessaire de définir les séparateurs utilisé dans le fichier *.csv. Dans l’exemple ci-après le séparateur du champ dictionnaire multiple est la virgule, valeurs possibles COLLECTIVITE1, COLLECTIVITE2, ….
Contrôle des imports :
Définir les règles de contrôle des imports (Avec ou sans Matching)
Cas sans Matching
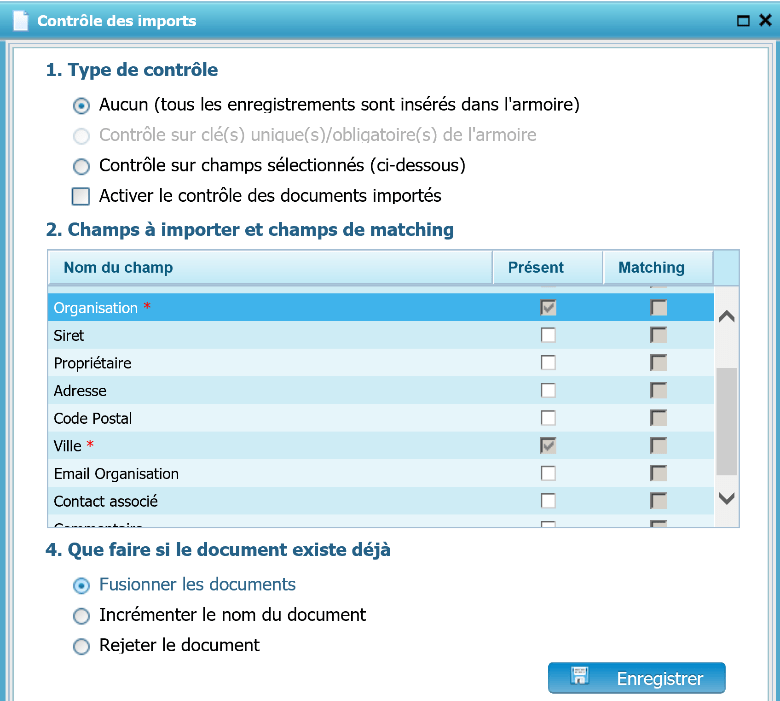
Cas avec Matching

Type de contrôle
- Aucun : Aucun contrôle n’est réalisé et tous les enregistrements seront intégrés à l’armoire
- Contrôle sur clé(s) unique(s) : L’armoire possède au moins une clé unique qui sera utilisée pour contrôler les doublons (champ grisé quand l’armoire ne possède pas de clé unique)
- Contrôle sur champs sélectionnées : L’armoire ne possède pas de clé unique, et il est possible de définir manuellement un ou plusieurs champs de contrôle des doublons
- Activer le contrôle des documents importés : si cette option est activée, les documents ne seront pas directement classés en GED mais nécessiteront la validation manuelle d’un utilisateur dans une interface de contrôle précise (accessible sur la page d’accueil)
- Champs à importer et champs de Matching
- Cocher le champ qui va être renseigné par le code-barres
- Colonne Présent : les champs cochés sont présents dans le fichier source. L’ordre des champs doit impérativement être respecté.
- Colonne Matching : les champs cochés définissent la clé de contrôle des doublons.
- Document existant
- Cocher le choix en cas d’import de document existant.
- Fusionner les documents
- Incrémenter le nom du document
- Rejeter le document
Cliquer sur « Enregistrer ».
Planification
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.
Import Matching zone code-barres
Ce type d’import permet d’alimenter l’armoire avec des documents contenant des codes-barres. Ces documents seront classés automatiquement dans la GED grâce à la lecture de la valeur contenue dans ce code-barres
Options générales :
Il faut donner un nom explicite à la tâche afin de pouvoir la tracer dans l’observateur d’évènements.

Définition de la tâche :
Il faut définir des paramètres pour la tâche :
- Type de tâche à réaliser : Import – Matching zone code-barres
- Choix de l’armoire : Choisir l’armoire de destination
- Répertoire d’import : Définir le chemin du répertoire contenant les images à importer
- Répertoire de rejet : Définir le chemin du répertoire de rejet
- Contrôle des import : Définir les règles de contrôle des imports
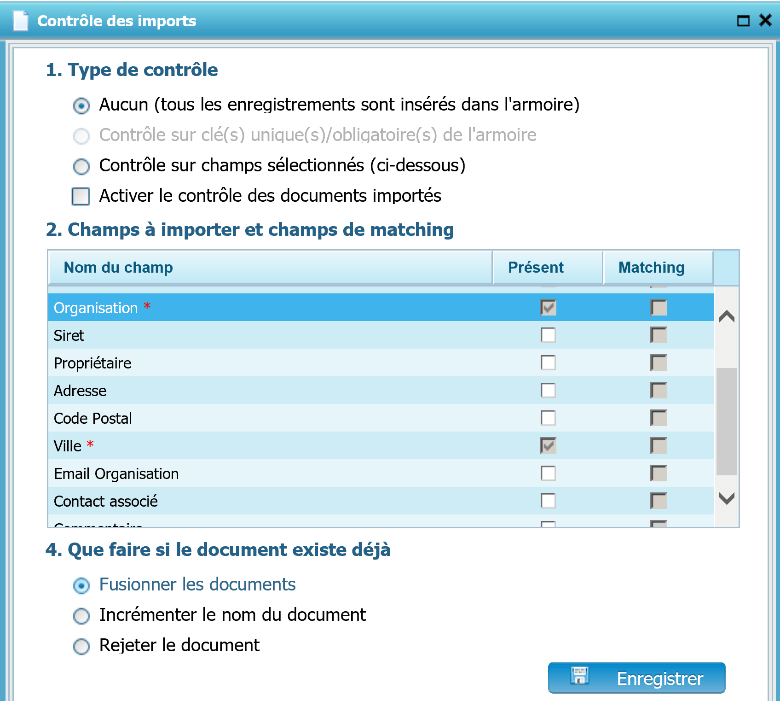
Type de contrôle
- Aucun : Aucun contrôle n’est réalisé et tous les enregistrements seront intégrés à l’armoire
- Contrôle sur clé(s) unique(s) : L’armoire possède au moins une clé unique qui sera utilisée pour contrôler les doublons (champ grisé quand l’armoire ne possède pas de clé unique)
- Contrôle sur champs sélectionnés : L’armoire ne possède pas de clé unique, et il est possible de définir manuellement un ou plusieurs champs de contrôle des doublons
- Activer le contrôle des documents importés : si cette option est activée, les documents ne seront pas directement classés en GED mais nécessiteront la validation manuelle d’un utilisateur dans une interface de contrôle précise (accessible sur la page d’accueil)
- Champs à importer et champs de Matching
- Cocher le champ qui va être renseigné par le code-barres. Si par exemple la valeur du code-barres est le numéro de client, nous cochons le champ « NUMERO »
- Document existant
Cocher le choix en cas d’import de document existant.
- Fusionner les documents
- Incrémenter le nom du document
- Rejeter le document
Cliquer sur « Enregistrer ».
Position de la zone de lecture
Ce lien nous ouvre la fenêtre suivante :
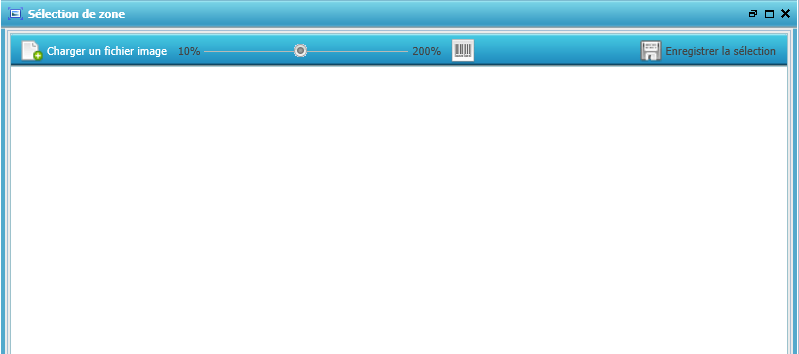
Cette fenêtre de numérisation va nous permettre de numériser ou d’importer un document code-barres de manière à renseigner la zone que l’on veut capturer.
Cliquer alors sur le bouton « Charger un fichier image » pour importer un document (seul un fichier tif ou jpeg sera accepté)
Le document apparaît alors à l’écran :
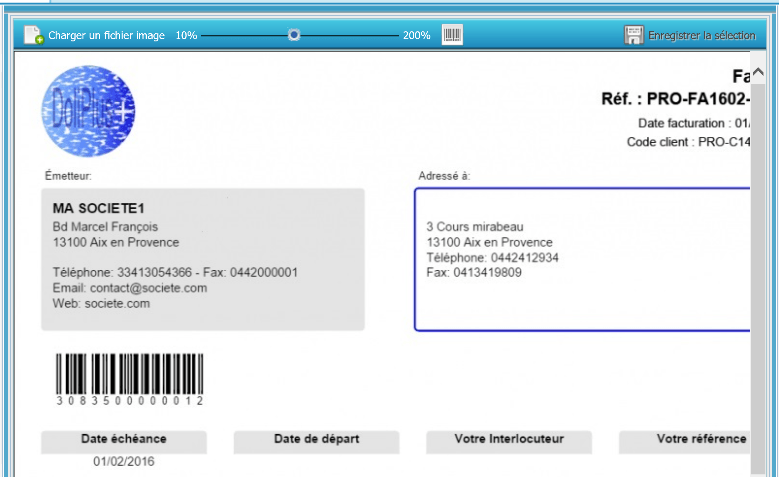
Cliquer ensuite sur 
pour paramétrer la zone à capturer.
L’icône de la souris devient alors une croix de sélection :
La fenêtre suivante s’ouvre :
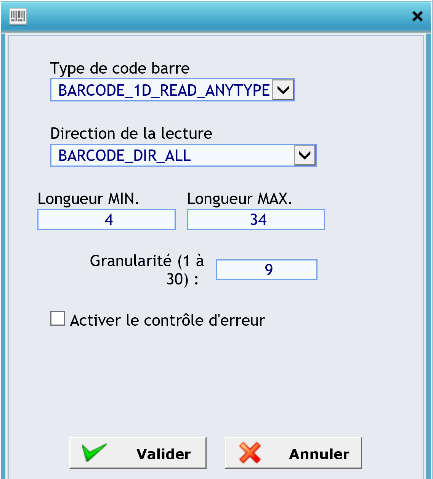
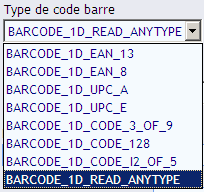
Type de code-barres :
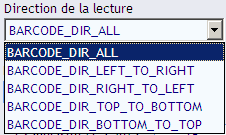
La direction de la lecture :
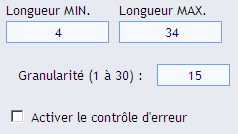
Les longueurs minimum et maximum, la granularité, et la possibilité d’activer le contrôle d’erreur :
Après validation, capturer la zone code-barres :
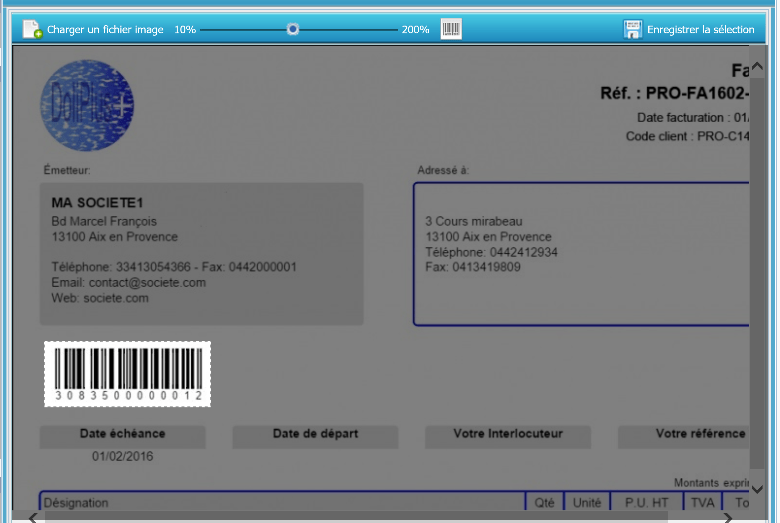
Cliquer sur « Enregistrer la sélection » pour valider la position du code-barres. Le paramétrage est alors réalisé.
- Classement des fichiers : Ce paramètre permet de définir un classement par défaut. Trois formats sont possibles :
- SD/SSD/FILE Le plan de classement est attendu, séparé par des / (Sous dossiers/ Sous dossier / Fichier)
- P2C dans ce cas, la dernière valeur qui compose le code-barres
- CBERIC derrière le séparateur, implique de positionner des séparateurs Eric
- Eliminer les séparateurs Multigest : si cette option est activée, les séparateurs Multigest utiles au classement des différentes rubriques seront supprimés. Si non coché, les rubriques seront bien créées mais les codes-barres de classement seront présents en début de chaque document créé
- Eliminer les autres séparateurs : même règle que ci-dessus, mais s’appliquant aux séparateurs autres que Multigest
- Suffixe code-barres : On définit ici la valeur lue dans le code-barres (dans le suffixe) que l’on ne souhaite pas garder
- Préfixe code-barres : Même chose que précédement, mais pour le préfixe (que l’on ne garde pas)
- Séparateur code-barres : défini le type de séparateur (tout caractère sauf le caractère *)
- Nombre maximum de pages : définir le nombre maximum de page pour la lecture
Planification
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.
Import SPOOL
Les tâches d’import spool AS400 et spool PDF sont liées à des logiciels spécifiques d’EFALIA.
Merci de nous contacter pour ces options.
Traitement OCR
La tâche planifiée de traitement OCR permet de réaliser des traitements OCR sur les documents d’une armoire. Cette tâche se définit avec une heure de début et une heure de fin et s’exécute sur le serveur.
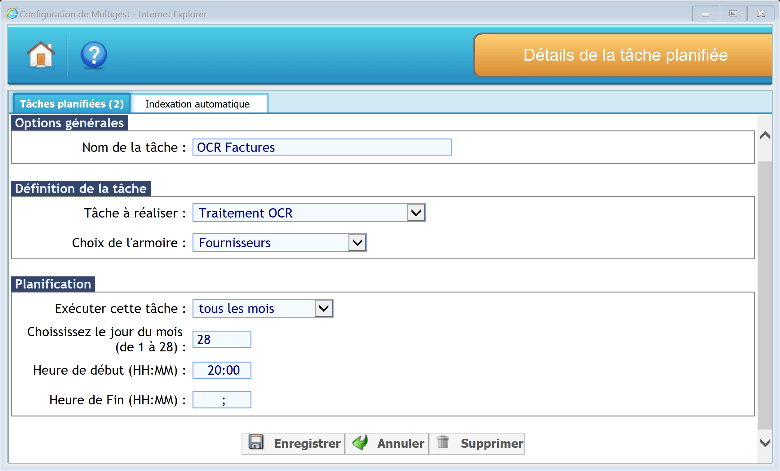
Options générales
Il faut donner un nom explicite à la tâche afin de pouvoir la tracer dans l’observateur d’évènements.

Définition de la tâche
Il faut définir des paramètres pour la tâche :
- Type de tâche à réaliser : Traitement OCR
- Choix de l’armoire : Choisir l’armoire de destination
Planification
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement et d’arrêt de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.
De plus, elles ne doivent pas être planifiées sur plusieurs armoires à la fois : une seule serait traitée.
Classement automatique
La tâche planifiée de Classement automatique permet de classer des documents automatiquement grâce à l’utilisation de codes barre nominatifs. Ces codes-barres nominatifs s’impriment dans les dossiers GED.
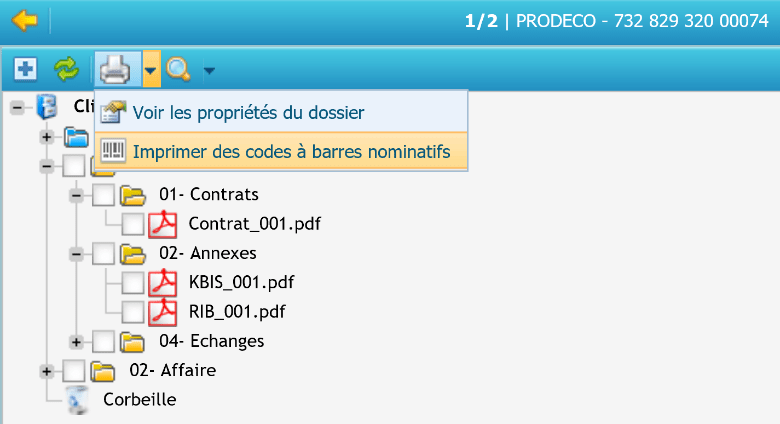
Une interface dédiée permet de spécifier sur quel(s) type(s) de document le séparateur va être généré.
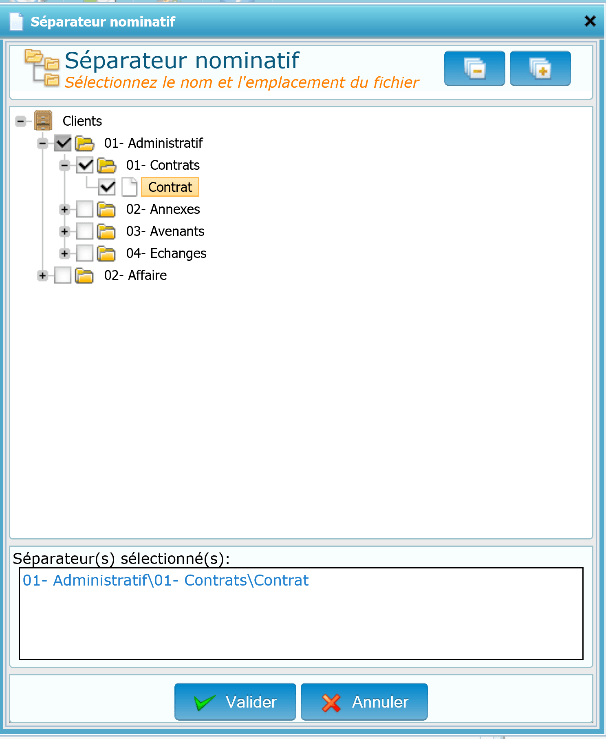
Cliquer sur le bouton « Valider » pour générer le code-barres du dossier.

Il suffit alors de numériser des lots de documents dans une bannette prévue pour cette tâche. La tâche ira lire les codes-barres nominatifs des fichiers, et les classera dans les dossiers en question.
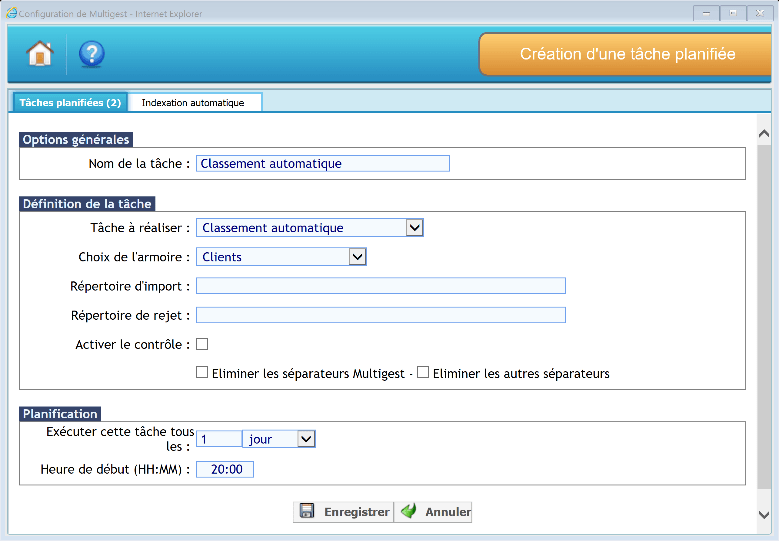
Options générales
Il faut donner un nom explicite à la tâche afin de pouvoir la tracer dans l’observateur d’évènements.

Définition de la tâche
Il faut définir des paramètres pour la tâche :
- Type de tâche à réaliser : Classement automatique
- Choix de l’armoire : Choisir l’armoire de destination
- Répertoire d’import : Définir le chemin du répertoire contenant les images à importer
- Répertoire de rejet : Définir le chemin du répertoire de rejet
- Activer le contrôle : si cette option est activée, les documents ne seront pas directement classés en GED mais nécessiteront la validation manuelle d’un utilisateur dans une interface de contrôle précise (accessible sur la page d’accueil)
- Eliminer les séparateurs Multigest : si cette option est activée, les séparateurs Multigest utiles au classement des différentes rubriques seront supprimés. Si non coché, les rubriques seront bien créées mais les codes-barres de classement seront présents en début de chaque document créé
- Eliminer les autres séparateurs : même règle que ci-dessus, mais s’appliquant aux séparateurs autres que Multigest.
Planification
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.
Archivage automatique
Cette tâche planifiée permet le lancement automatique des tâches d’archivage.
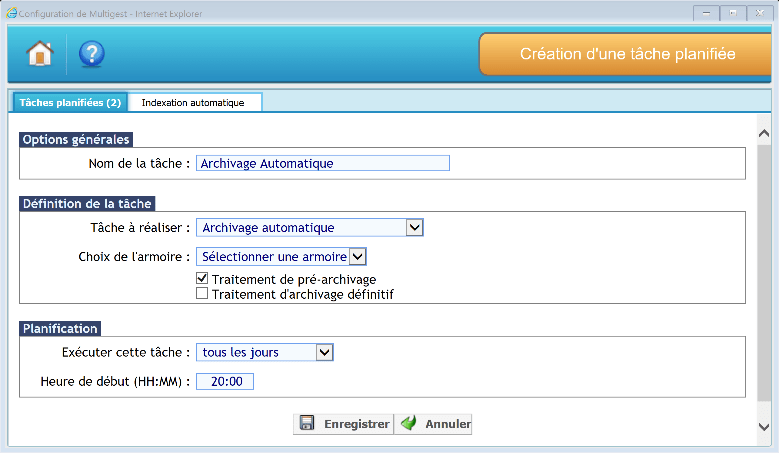
Options générales
Il faut donner un nom explicite à la tâche afin de pouvoir la tracer dans l’observateur d’évènements.

Définition de la tâche
Il faut définir des paramètres pour la tâche :
- Type de tâche à réaliser : Classement automatique
- Choix de l’armoire : Choisir l’armoire de destination
- Choix du traitement : pré-archivage et/ou archivage définitif
Planification
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.
Classement automatique bannettes
Cette tâche planifiée permet de lire automatiquement des séparateurs de bannettes et permet donc aux utilisateurs de numériser dans une seule bannette. Les lots numérisés devront contenir des séparateurs de bannettes.
Les séparateurs de bannettes sont générés depuis l’interface d’administration des bannettes.

Le code-barres apparait :

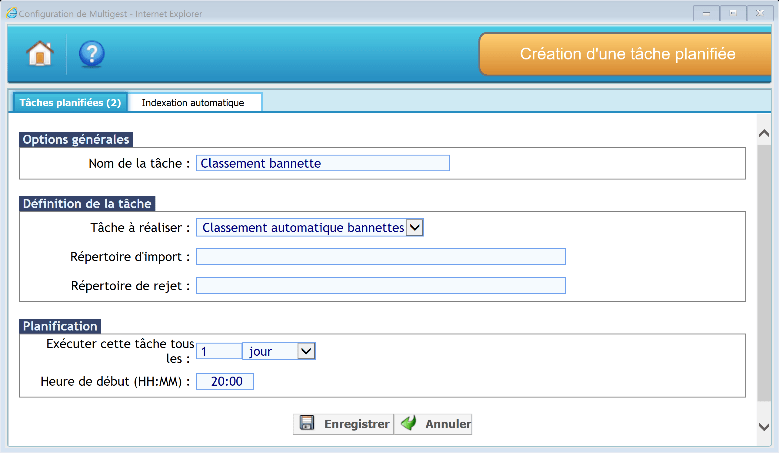
Options générales
Il faut donner un nom explicite à la tâche afin de pouvoir la tracer dans l’observateur d’évènements.

Définition de la tâche
Il faut définir des paramètres pour la tâche :
- Type de tâche à réaliser : Classement automatique bannettes
- Répertoire d’import : Définir le chemin du répertoire contenant les images à importer
- Répertoire de rejet : Définir le chemin du répertoire de rejet
Planification
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.
Transfert inter-armoire
Cette tâche planifiée permet de réaliser des transferts de document entre des armoires. Il faut au préalable créer un lien entre deux armoires (Cf. Gestion des liens inter-armoires).
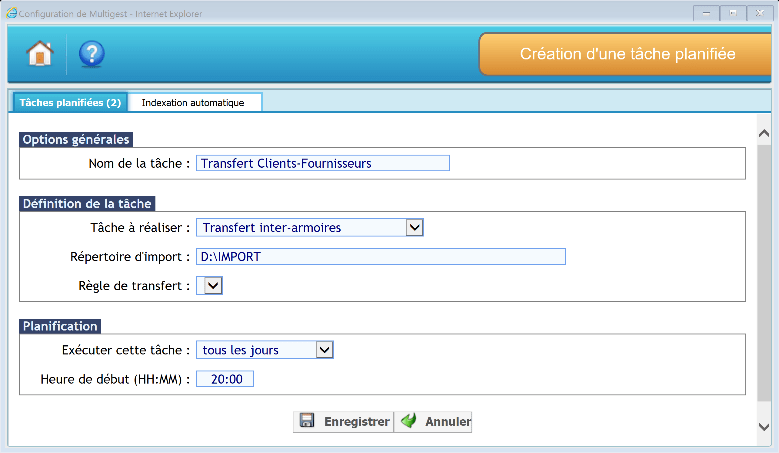
Options générales
Il faut donner un nom explicite à la tâche afin de pouvoir la tracer dans l’observateur d’évènements.

Définition de la tâche
Il faut définir des paramètres pour la tâche :
- Type de tâche à réaliser : Transfert inter-armoires
- Répertoire d’import : Définir le chemin du répertoire contenant les documents à importer
- Régle de transfert : Sélectionner la régle de transfert paramétrée dans la gestion des transferts de dossiers
Planification
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.
Journaux
L’accès aux journaux se fait en cliquant sur le bouton « Logs des tâches planifiées » dans l’interface d’administration des tâches planifiées.
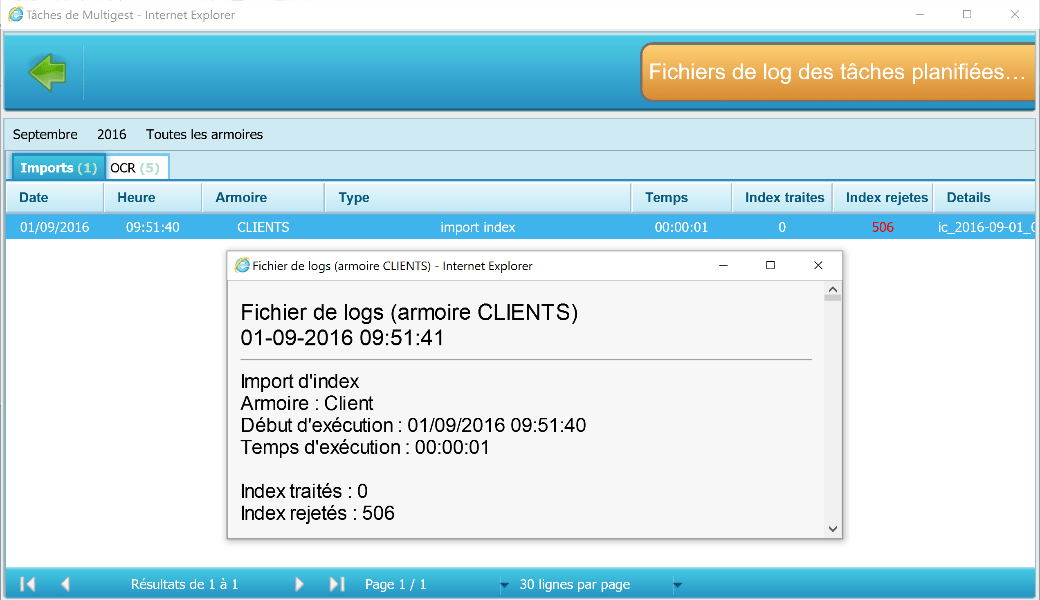
Accès au journal actif
Liste des tâches exécutées ou planifiées
Indexation automatique
Pour créer une nouvelle tâche d’indexation cliquer sur le bouton « Nouvelle règle d’indexation » dans l’onglet « Indexation automatique ».
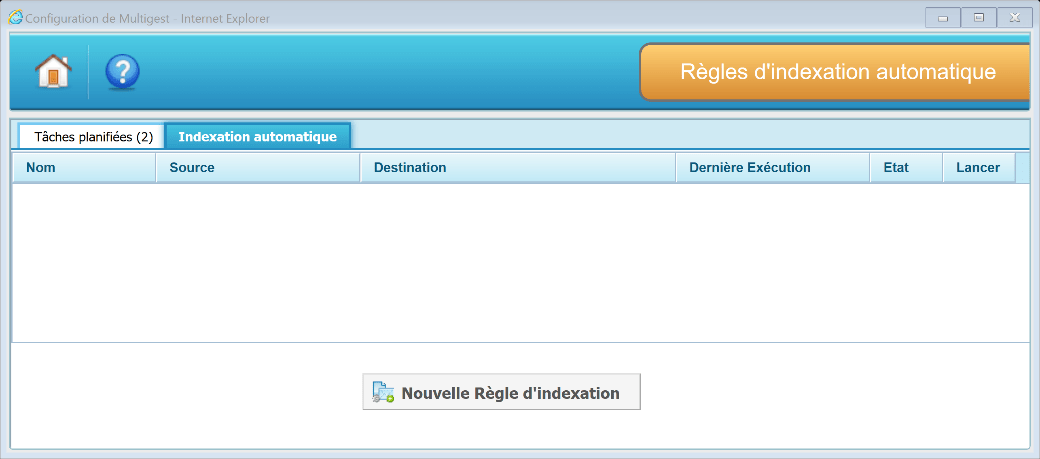
Deux types d’indexation automatique sont disponibles :
- Indexation Mail
- Indexation Bannette
Indexation Mail
En fonction du paramétrage, il est possible d’indexer en GED :
- Le mail complet (corps du mail + pièces jointes) au format eml
- Toutes les pièces jointes d’un mail
- Seulement les pièces jointes configurées d’un mail
Dans tous les cas, l’indexation d’un de ces éléments donnera lieu à la création d’un dossier GED.
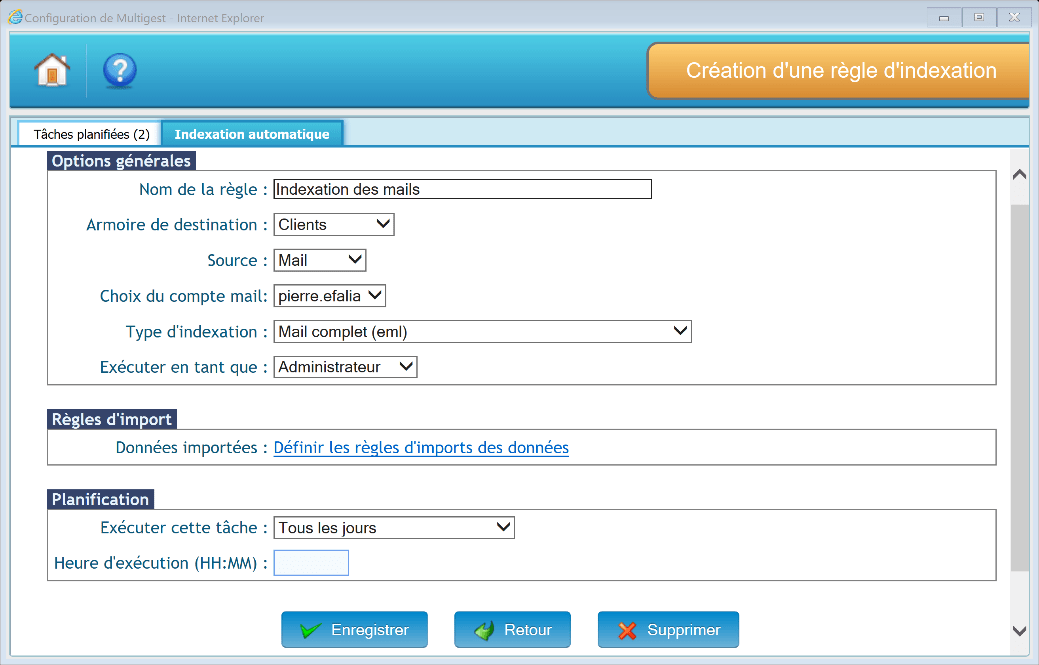
Options générales
- Nom de la règle : Nom que portera la règle
- Armoire de destination : Armoire dans laquelle seront indexés les documents
- Source : Détermine le type d’indexation (Choisir « Mail »)
- Choix du compte mail : Compte mail dont les mails sont à indexer. Les comptes mails doivent au préalable être paramétrés dans le menu « Options générales » puis dans l’onglet « Messagerie » (Cf. Onglet Messagerie)
- Type d’indexation : Détermine ce qu’il faut précisément indexer :
- Mail complet
- Seulement les pièces jointes
- Seulement les pièces jointes répondant aux règles d’import, etc.
- Exécuter en tant que : Cet utilisateur sera considéré comme le créateur du dossier dans la GED
- Règles d’import : Type d’indexation Mail complet (eml)
Cliquer sur « Définir les règles d’import des données ».
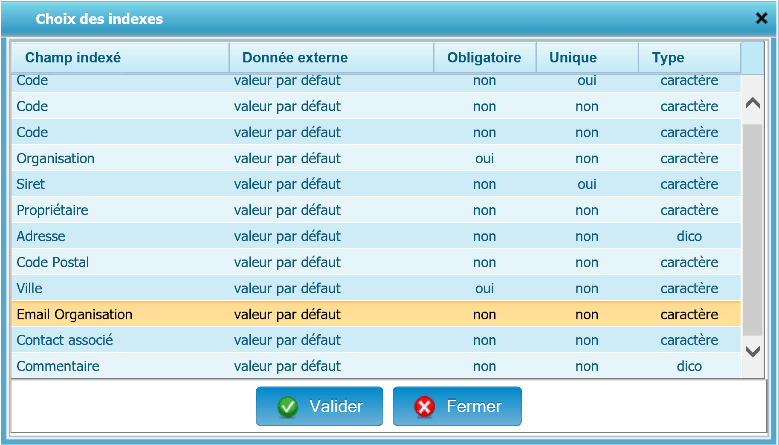
- Champ indexé : Liste les champs d’index de l’armoire de destination sélectionnée
- Donnée externe : Permet l’attribution d’une valeur pendant l’indexation parmi les possibilités suivantes :
- Valeur par défaut : Valeur par défaut déclarée en base
- Expéditeur : Adresse mail de l’expéditeur
- Destinataire : Adresse mail du destinataire
- En copie : Adresses mails en copie
- Objet : Objet du mail
- Date d’envoi : Date d’envoi du mail
- Date du jour : Date du jour de l’indexation automatique
- Numéro chrono : Identifiant en base
- Obligatoire : Indique si la valeur est obligatoire (comme défini dans la structure de l’armoire). Remarque : les champs obligatoires nécessitent l’assignation d’une donnée externe.
- Unique : Indique si la valeur est unique comme défini dans la structure de l’armoire
- Type : Indique le type de la valeur comme défini dans la structure de l’armoire
- Règles d’import : Seulement pièces jointes
Si on utilise les options « Seulement les pièces jointes (toutes les pièces ou répondant aux règles d’import », il faut définir des règles d’imports pour les documents en pièces jointes.
Cliquer sur « Définir les règles d’import des documents ».
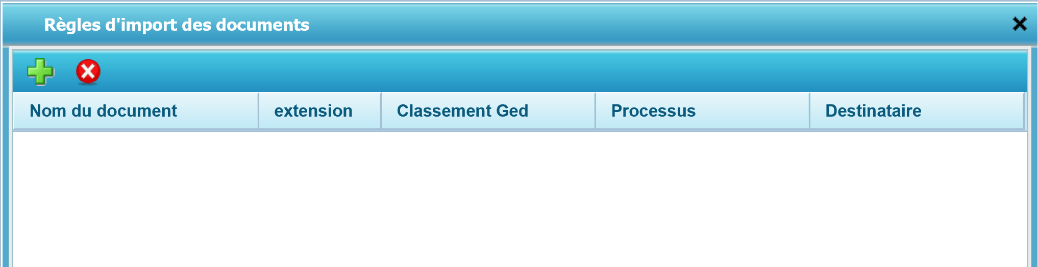
- Nom du document : nom du fichier
- Il est possible d’utiliser dans le nom saisi ; le caractère (*) qui équivaut à n’importe quelle chaîne de caractères.
- Exemple 1 : La saisie de ‘facture_F*’ permettra, entre autres, l’indexation des documents ‘facture_F1’ et ‘facture_F2’.
- Exemple 2 : Le caractère (*) équivaut “à tous les noms”
- Extension : Extension du document
- Il est possible ici aussi de faire usage du caractère (*)
- Il est également possible de saisir plusieurs extensions, en les séparant par un point-virgule
- Exemple 1 : pdf
- Exemple 2 : doc;docx
- Exemple 3 : doc* (équivaut à l’expression de l’exemple 2)
- Exemple 4 : * équivaut « à toutes les extensions »
- Classement GED : Sélection du plan de classement
- Processus : Processus Workflow associé (suivant le plan de classement sélectionné)
- Destinataire : Le créateur du document
Planification
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.
Indexation Bannette
Ce type d’indexation permet l’indexation en GED des documents présents dans une bannette sélectionnée.
L’indexation d’un de ces éléments donnera lieu à la création d’un dossier GED.
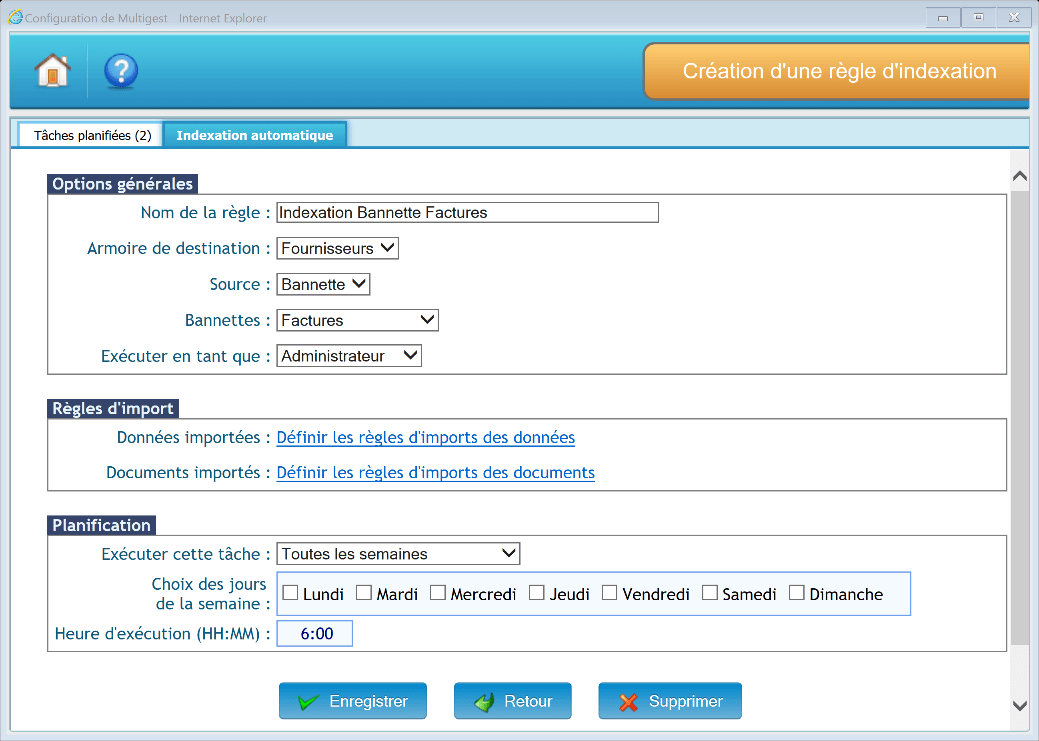
Options générales
- Nom de la règle : Nom que portera la règle
- Armoire de destination : Armoire dans laquelle seront indexées les documents
- Source : Détermine le type d’indexation (Choisir « Bannette »)
- Bannette : Bannette dont les documents sont à indexer
- Exécuter en tant que : Sélection d’un utilisateur habilité sur la bannette qui sera assimilé comme le créateur du dossier GED
- Règles d’import : Données importées
Cliquer sur « Définir les règles d’import des données ».
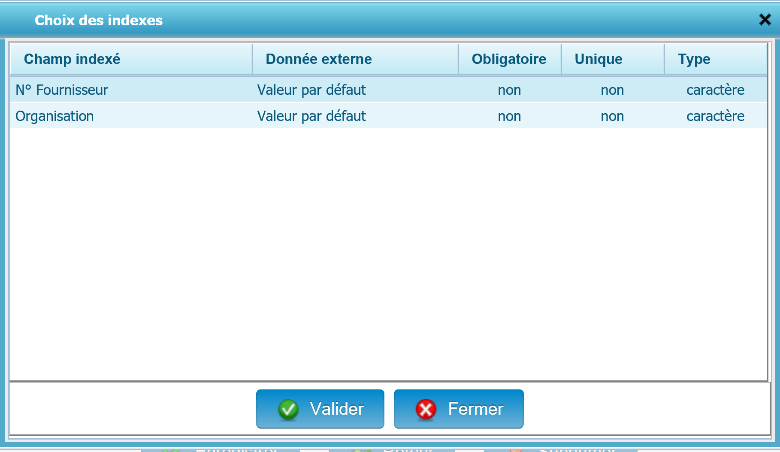
- Champ indexé : Liste les champs d’index de l’armoire de destination sélectionnée
- Donnée externe : Permet l’attribution d’une valeur pendant l’indexation parmi les possibilités suivantes :
- Valeur par défaut : Valeur par défaut déclarée en base
- Date du jour : Date du jour de l’indexation automatique
- Numéro chrono : Identifiant en base
- Nom Fichier : Nom d’origine du fichier
- Nom Bannette : Nom de la bannette
- Utilisateur : Utilisateur défini dans le champ “Exécuter en tant que”
- Obligatoire : Indique si la valeur est obligatoire (comme défini dans la structure de l’armoire). Remarque : les champs obligatoires nécessitent l’assignation d’une donnée externe.
- Unique : Indique si la valeur est unique comme défini dans la structure de l’armoire
- Type : Indique le type de la valeur comme défini dans la structure de l’armoire
- Règles d’import : Documents importés
Cliquer sur « Définir les règles d’import des documents ».
Ici, on peut définir les règles d’import des documents présents dans la bannette. L’utilisation étant identique, se référer à la partie « Définir les règles d’imports des documents » de la partie Indexation Mail.
Précisions : La colonne « Créateur/Acteur » précise le créateur du Workflow et premier acteur si celui-ci est à déterminer.
Planification :
Il est possible de planifier la tâche tous les jours, toutes les semaines ou tous les mois ainsi que l’heure de lancement de la tâche.

Cliquer sur « Enregistrer » pour sauvegarder les paramètres.